文献管理软件Zotero基础及进阶示范
我的文献管理软件使用历史极其悠久,先后是:
- Endnote Windows版:十多年前,一位师兄,如今的小牛,曾经用[Endnote]下载过十年的JPSP论文,然后一篇一篇批注,从那时起,文献管理软件给我留下了极其深刻的印象;
- 老友创业团队开发的[NoteExpress],当之无愧的国内Windows下文献管理No.1。因为太熟悉它的诞生与发展历程,所以它也是我使用年头最长的文献管理软件,积累的文献库好几G。
- Endnote Mac版:07、08年慢慢转到Mac下,不得不抛弃[NoteExpress]了。

在Mac下,先后试用与比较过[Papers2]与[mendeley]。但是因为种种原因,最终还是回到Zotero下。有感于国内对这么一款极其优秀的开源软件非常不了解,特别介绍它的入门与进阶知识。
注册Zotero新账号并下载
登陆https://www.zotero.org/user/register/,注册一个自己的Zotero账号,请特别记住,username会直接生成个性域名,别乱起,未来会有些不方便。

下载Zotero单机版,也就是Zotero Standalone。Mac、Windows等通用。
http://www.zotero.org/download/
也可以下载firefox插件版,但是我更推荐单机版。两者的区别如下:

下载之后安装默认提示一路安装。
配置Zotero
打开Zotero,找到[首选项]或偏好:

在同步一栏输入前面注册的账号,这样,文献库可以同步到[Zotero]官网。

创建一个用来保存文献库的根目录,假设是:/users/ouyang/dev/zotero 继续配置:

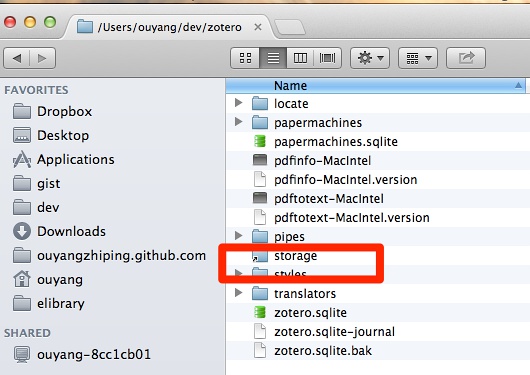
[Zotero]官网默认的存储空间有限,所以,我们需要一个小技巧,将文献库里面保存PDF文档的目录,分离开,放到[dropbox]目录下同步。回到刚才创建的:/users/ouyang/dev/zotero 目录,其中的storage目录是拿来保存PDF等文档的,将其剪切到[dropbox]目录下,如下图所示:

打开终端或shell,创建一个软连接,让[Zotero]认出该目录:
ln -s /users/ouyang/dropbox/zotero/storage /users/ouyang/dev/zotero/storage
回头看,/users/ouyang/dev/zotero 目录下多了一个软链接,表示成功了。

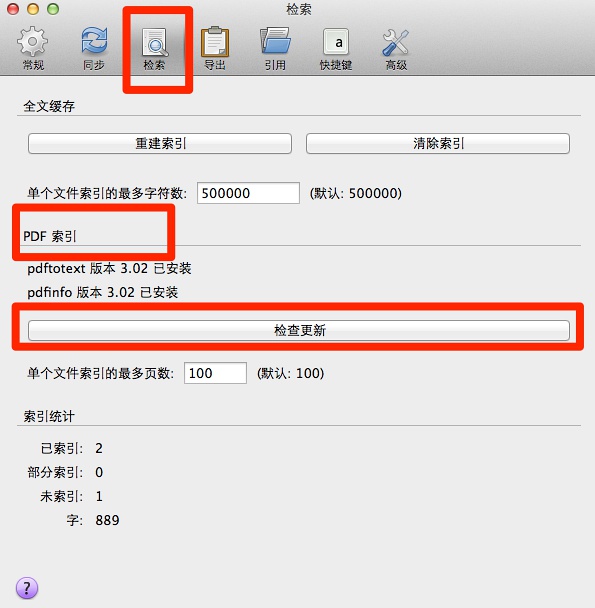
接下去,在配置这里安装pdf索引:

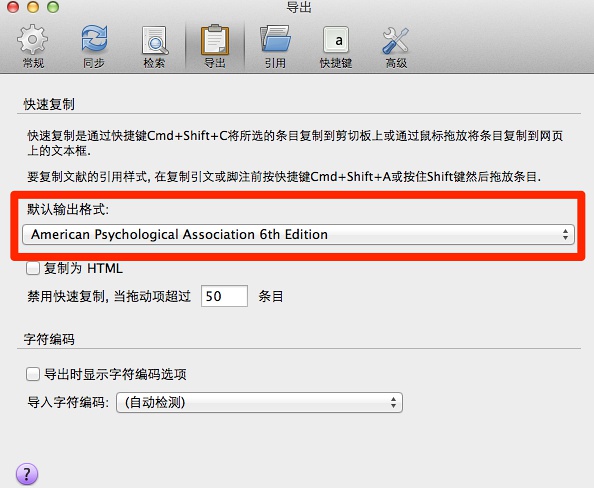
以及,将默认输出格式,更改为APA第六版:

导入第一篇文献
好了,准备工作做完了。现在,让我们导入第一篇文献。Zotero支持以下六种导入方法:
- 互联网自动识别:Web Translators (URL bar icon)
- 手动输入:Manual Input or Edit From a bibliographic
- 文件导入:format (RIS, BibTeX, MARC, etc.)
- 通过标示符增加:Add by identifier (DOI, ISBN, PMID)
- 通过PDF元数据识别:Add PDF then Retrieve Metadata
- 从网页识别:Get any Webpage with basic data
先让我们找找成就感,从最容易的开始。通过Web Translators,互联网自动识别。
打开豆瓣网站,随便找一本书,让我们以前一篇文章[心智十二宫]中的[我生活的种种模式]为例,它的豆瓣网页是:
http://book.douban.com/subject/1065156/
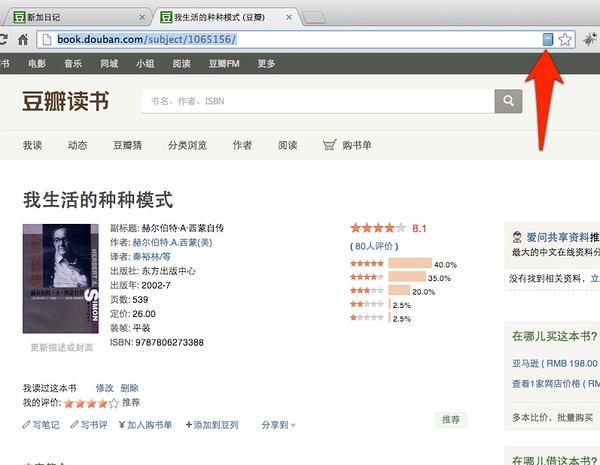
请特别注意,你的Chrome浏览器上会多出一个图书的标识!点击它,保存即可。

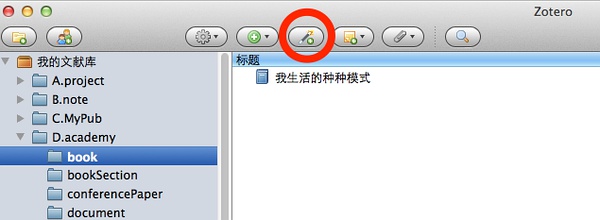
打开[Zotero]软件,我们会发现,之前鼠标定位的子类下面,会多出一个条目,如下图所示:

更有趣的是,[我生活的种种模式]这本书的豆瓣网址直接保存下来了,下次直接点击即可。这就是[Zotero]极其强大的Web Translators 功能,它可以根据世界上主要的信息资讯网站,生成相应的图标,比如,豆瓣的图书就是图书的小符号,维基百科则是维基类的小图标。更强大的是,一切你想保存资讯的网站,你可以定制Web Translators,然后保存在之前我们创建的根目录:
/users/ouyang/dev/zotero 下面的translators目录里面。如下图所示:

小提醒:如果没有多出这个图标,Web Translators 功能没有生效,是插件安装失误,请通过Chrome网上应用店,安装:Zotero Connector。
导入维基百科
通过集体智慧的协作,目前[Zotero]软件的Web Translators已经几乎支持世界上主要高质量资讯网站,如维基百科、Google学术。现在,让我们继续找点成就感,自动导入维基百科试试看。
学习一门新学科,常常需要知道学科中的牛人,维基百科的列表功能就是非常强大的资讯源。我们打开它的认知科学家列表,基本代表了功成名就的认知科学家们:
http://en.wikipedia.org/wiki/List_of_cognitive_scientists
我们会发现,这次图标与保存豆瓣的图书图标不一样了!哈哈,变成一个百科全书的图标了,如下图所示:

我们仍然点击保存,好的,文献库就有了!

嗯?这次保存下来的为什么与上次的不太一样!多了个快照?点击看看!原来这是[Zotero]软件的另一个强大而贴心的功能,它自动将网页的快照拍摄下来了。这样,未来这个网页消失了,我们的资讯还没丢失!
导入Google学术
一次一次导入一篇,并不是学术研究时的常见现象。更常见的是,批量导入多篇。让我们以Google学术库为例。打开Google学术库,我们输入检索关键词,[netlogo],一个网络仿真常用软件。
http://scholar.google.com/scholar?q=netlogo&btnG=&hl=zh-CN&as_sdt=0%2C5
我们发现,这次浏览器的图标变成一个文件夹!这就意味着,有多篇文献识别出来,需要保存。

点击文件夹图标,然后弹出对话窗口,我们挑选一篇引用率排第一、带PDF文档的保存下来:

打开[Zotero]软件,我们怒了!作为一个开源软件,它为什么能这么贴心!Google学术里面带PDF文档,刚才弹出窗口提示有PDF字眼的,它连关联PDF也关联起来了!如下图所示:

通过标示符增加
总有一些文献,google学术检索不出来(虽然,这个概率越来越低)。这个时候,需要我们手动添加。
让我们以前一篇文章[我们为什么害怕学习]为例,通过豆瓣,找到[Why Don’t Students like School]这本书的ISBN是:9780470591963。如下图所示:

我们启动[Zotero]软件,点击通过标示符增加的按钮:

输入ISBN:9780470591963。即可添加成功,如下图所示:

这次我们继续怒了!开源软件的贴心程度已经超出我们想象,这次保存下来的图书信息,多了什么呢!原来,多了两条笔记,来自出版商的介绍!
好的,接下去,我将我写的笔记保存进来。选中图书名字,点击右键:添加笔记。一般用户可以直接在这里写笔记。
如果是Markdown与Mou用户,则不要在这里直接写笔记,代码会额外混乱,点击html选项:

将Mou生成的html内容复制过去:

效果如下图所示,非常漂亮的笔记出来了!

小提醒:不过这么整理还是略微有些麻烦,笔者正在想办法,将[Zotero]与[Mou]、[Evernote]的配合更智能化。
导入Endnote数据库
好的,我们有大量的文献是使用其它文献管理软件管理的,怎么导入?以最流行、最常用的[Endnote]为例。选择File=>Export,如下图所示,记得一定要将导出风格选为:Endnote Export:

然后,导出的文本文件,直接导入到[Zotero]中即可,更复杂的导入方法,可以参考各类教程。

导入PDF文档
有不少之前下载好的PDF文献,尤其是一些本来是从学术数据库下载的文献,它们支持PDF元数据功能,这样就非常省事,可以直接拖到[Zotero]中来,然后会自动将其文献信息识别出来。
如下图所示,我们将一个PDF文档拖到自己的项目文件夹中来,然后选择右键:[抓取PDF的元数据],

就自动根据PDF元数据生成相关文献信息了:

Zotero进阶示例:文献可视化
在上面这个导入例子中,我们用的是同事的一篇学位论文的参考文献库,研究的主题是青少年与社会网络分析。我们尝试对这些文献进行可视化分析。
首先,需要安装插件papermachines,下载xpi文件,http://chrisjr.github.com/papermachines/,文件地址是:http://www.papermachines.org/download/papermachines-0.4.4.xpi
我们通过[Zotero]的插件安装,如下图所示:

然后点击:Install Add-on from File…

找到之前下载的xpi文件,安装好,重启[Zotero]。
然后选中我们要进行文献分析的库,如下图所示:

第一次运行,需要继续重启[Zotero],重启之后,就好了,点击各类,查看文献可视化的结果:

这是以标签云形式对一百多篇文献进行分析的结果,接下去,我们可以换个视图:

我们可以清晰地发现,我同事的学位论文中,引用的文献聚焦在:青少年吸烟、社会网络、同辈群体、关系等主题上。
Zotero更多资源
Zotero还有更多进阶玩法,在这里不展开讲了。各位感兴趣的敬请查阅资料:
入门教程
- zotero中文快速入门:http://www.zotero.org/support/zh/quick_start_guide
- Zotero中文入门介绍:http://www.zotero.org/support/_media/zotero_miniguide.pdf
- 台湾中央研究院计算中心关于Zotero的介绍:http://ascc.sinica.edu.tw/iascc/articals.php?_section=2.4&_op=?articalID:3934
- MIT图书馆的教程:http://libguides.mit.edu/zotero
- Washington University St. Louis: http://libguides.wustl.edu/zotero
- Zotero入门介绍:http://www.slideshare.net/adam3smith/intro-zotero *你为什么需要Zotero:其中关于六类人的漫画描述,极其生动。
- 研究生2.0关于Zotero的介绍
- 老杨与他本科同学写的Zotero介绍
核心插件
- Zotero插件大全
- zotero插件集合
- Papermachine
- Zotfile
- Multi-Lingual Zotero
- Qnotero
- Translator testing
- Zotero隐藏的偏好:http://www.zotero.org/support/preferences/hidden_preferences
- RTF Scan
版式风格在线可视编辑
整合工具
- Omeka : Zotero开发学校的另一个项目
- editorsnotes
- Zotero开发机构的其他项目:http://chnm.gmu.edu/research-and-tools/
移动支持
http://www.zotero.org/blog/zotero-apps-go-mobile/
小结
与其说[Zotero]是一个文献管理软件,不如说是一个知识管理平台。选择开源软件,就是选择一个生态链,这是与商业软件,如[Papers2]、[mendeley]或[Endnote]非常不一样的地方。
在前文文献管理软件Zotero基础及进阶示范中,主要介绍了作为文献管理工具、学术工具的Zotero。今天说说作为一个超级强大的知识管理工具的Zotero,比如书签管理、网页收藏、分类知识体系、快速学习等。
Tag体系的问题
这么多年,我认识的朋友,除非是超级勤奋的,一般正常人,很少有坚持使用tag系统成功的。它 存在什么问题?
- 在收藏的时候,无法坚持输入多个tag系统,有的多,有的少,甚至有的没有,导致最后凌乱;
- 当事先非常规整的Tag系统,一旦由于对某个Tag的描述改变,导致很多前面的Tag更改不及时;
- 需要记忆与复习的时候,Tag提取不便,因为Tag系统总会随着时间崩溃
简而言之,Tag系统的本质并不适合分类,而是【印象】系统,这才是Tag系统的本意。但是,太多的人将其当做分类工具在使用,最后导致得不偿失,付出的精力往往得不到相应的产出。人类的最佳知识表征结构是什么?
我提过多次的MIT认知科学家Josh(今年将来中国做邀请演讲)发表在pnas的论文中,比较了抽象知识的不同表征结构,如星形结构、聚类结构、环形结构等等,最终还是意识到,人类的最佳知识结构是树形结构。只有树形结构,才是最符合人类认知特点的一种结构,从树的上一层到下一层,是具备唯一通道,便于大脑将知识从记忆底层快速提取出来,符合人类大脑是个认知吝啬鬼的特点;树又是兼具横向扩展与纵向扩展能力的最优雅的结构。所以,儿童学习词汇时,最初是将物体进行扁平互斥的划分并对应到不同名称,当他们意识到,以树形结构来学习时,他们的认知开始大幅度发展。这种神秘的树形结构不仅仅影响到儿童早期的认知发展,在科学界,也处处可以看到神秘之树的身影,如门捷列夫的元素周期表开创近代化学;卡尔·冯·林奈使用树形结构创立了对自然世界的基本分类法。
Tag系统与树形结构相反,它实质上是非常违背人们学习与记忆提取的规律的。尤其当Tag更多是Tag,而不是树形结构的时候。它是个云形结构,会随着时间变迁而动荡。记忆恰巧需要的不是这类时间动荡。所以,太多人对Tag系统进行了种种改良,这种改良本质上,都是在放弃Tag自身,使用了主从类的,更贴近树形结构的改良。
Zotero的分类
作为对Tag系统的改良。在Zotero中,我们不推荐将Tag作为分类使用,而更多当做【印象】使用!请记住,Tag始终会随着时间而动荡甚至走向崩溃!所以,更重要的是,你当时当下对该文档的【印象】,而不是【分类】!
那么,如何更好分类?
- 以基本属性作为分类,基本属性是你可以很快归类的,不太会随时间动荡的;
- 再使用搜索代替随时间动荡的内容;
- 不再将Tag作为【分类】属性;而是当下【印象】工具。
如下图所示:

作为知识管理工具的Zotero示例
Zotero提供了一个非常强大的自定义搜索功能。类似于自动归类的文件夹。以下试举几例。
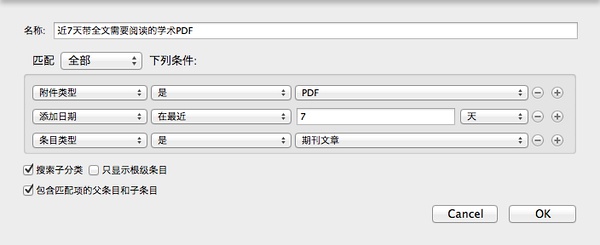
本周带全文需要阅读的学术论文PDF
点击:我的文献库,右键,新建搜索。如下图所示:

创建条件,如下图所示:

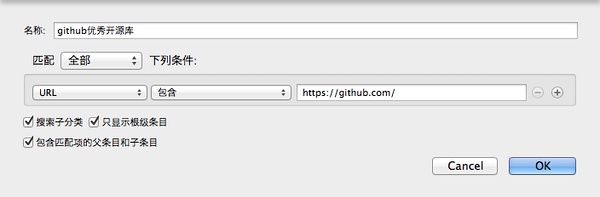
github优秀开源库收藏

豆瓣好书精选

诸如此类不等。总之,可以尽情发挥想象力,定制出各类自动化的搜索分类。进一步,有熟悉js脚本的朋友,完全可以打开根目录,自定义自己的条目类型,如github、如微博。
事实上,大量的条目类型,已经由全世界网友提供了并且编写好了各类脚本,如推特、如维基百科、如readability、如Google图书、如Google博客。参见:
https://github.com/zotero/translators
如果自己撰写,可参考文档:
http://niche-canada.org/member-projects/zotero-guide/chapter1.html http://www.huangwei.me/blog/2011/01/06/write_zotero_translator/
作为快速学习的Zotero
维基百科是最佳的入门知识首选,Zotero可以创建知识的收藏时间线,如下图所示:

全文搜索的改进
Zotero由于是西方开源者开发,对中文、全文检索能力有时候不如Evernote等,如何改进?
由于Zotero是条目存储与附件相互分分离的。这么一来,只要使用你的桌面搜索工具,将Zotero的存储目录,即storage目录,加入到相应偏好里面。那么,你可以轻而易举拥有更强大、更快捷地,对你所有存储的网页快照、文献的全文检索。
在Windows下,可以使用Google桌面搜索;在Mac下,则自带的spotlight已经支持。如下图所示:

打开research.html页面一看,这就是保存在我们本地的网页快照:
file://localhost/Users/ouyang/Dropbox/zotero/storage/3PHJNDJE/research.html
然后打开Zotero,输入存储中的唯一标示符:3PHJNDJE。如下图所示,这样就非常快地借助超级强大的第三方全文检索工具,定位到Zotero中的内容了:

进一步,因为Zotero完全开源,包括同步去向,也可以搭建自己的同步服务器,在同步服务器上使用elasticsearch等搭建自己的超强全文检索库。
继续小白文风格,多图,高手慎入。很多亲朋好友们,都是卡在上手工具的那么几个关键小步骤。导致完全回避好的方法与工具,使用上个世纪的研究理念干苦力活。
人有时会念旧,十多年前,互联网可不是今天这样子。那时,我们谈论R语言、数据挖掘与文献管理,我们在谈论什么?昨晚,偶尔翻出当年担任版主的统计论坛:百岛潮统计论坛,时光如水,百岛潮当年单纯的气质已默默成为每人青春回忆中美好的一部分。
如今这个时代,知识看似垂手可得,研究日益变为职业与市场交易,研究的技术也跟随演化。继续前两天话题,将研究辅助工具再次说透彻点。这次侧重社交与移动。
移动的Zotero
以iPad的Safari为例,安卓的Chrome步骤大同小异。说说如何给Safari增加保存到Zotero文献库的选项。
步骤1:随便选一个页面,将它加入到Safari书签。如下图所示:

步骤2,打开iPad的设置,找到Safari,如下图所示,将【总是显示书签栏】给选为【on】。

步骤3,打开iPad的Safari,然后触摸书签,再触摸【书签栏】,如下图所示:

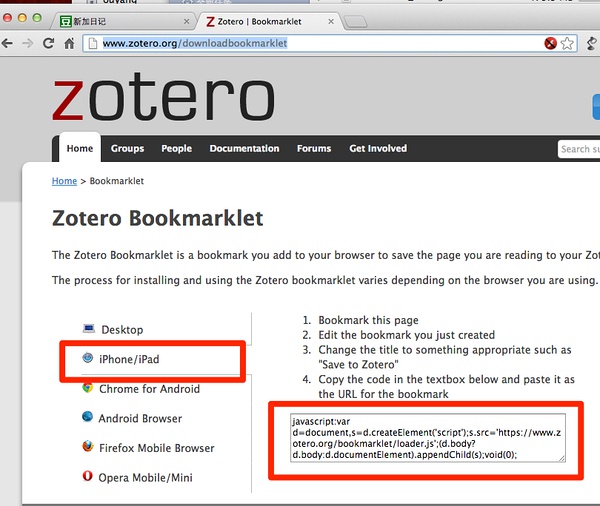
步骤4:好的,关键点到了!将之前在步骤1保存的Zotero,点击编辑,将网址更改为Zotero书签的内容。从这里复制:
http://www.zotero.org/downloadbookmarklet
如下图所示:

复制之后,效果如图:

步骤5:好的,大功告成,在平板上的Zotero.org网站,登陆一下你的账号,记住选择记住密码。然后随便挑选个论文库或者豆瓣读书试试看,我们会发现成功保存到云端的文献库中了。
平板的Zotero
一般习惯用Kindle读电子书,读PDF还是习惯平板设备。主要是批注速度、阅读速度较快。以下以iPad为例。同样,Zotero也支持安卓设备。
先从神器1Notability讲起。
Notability是一个好评如潮的PDF阅读与批注APP。如何与Zotero配合?关键点在第一篇文中的小技巧,将Zotero的条目与存储相互分离。Zotero的数据库仅仅用于保存条目等;而Dropbox用于保存PDF、网页快照等。
这么一来,通过Notability自带的与Dropbox自动同步的功能,就可以非常愉快与轻松地使用手指或者触控笔手写笔记。
步骤如下,
步骤1:购买并安装Notability
它非常物美价廉。安装后打开。
步骤2:在dropbox下面的zotero目录创建note目录
请记住!在老文文献管理软件Zotero基础及进阶示范 第一步建立的Dropbox下面的Zotero新建一个笔记目录!这是用来存放自动同步的笔记的,与存放PDF、电子书、网页快照的storage目录平级!如下图所示:

步骤3:设置Dropbox自动同步
回到Notability的设置里面,继续在import dropbox里面设置。如下图所示,选择设置:

打开之后,选择自动同步选项:

一步一步往下设置,选择Dropbox。

这是个比较关键的步骤,未来很多技巧会用到这个路径。所以,请务必选择刚才步骤2的[note]目录。

接下去,选择同步格式了。又是个关键步骤,一般建议选择rtfd格式。这是富文档格式,这样才能够直接保存录音、图片等。

步骤4:导入Zotero里面保存的PDF文档,并写批注
好的,大功告成。现在点击import,然后导入dropbox=>storage目录下面的pdf即可。如下图所示:

导入时,会询问你是否创建新笔记,选择是即可。打开pdf,开始阅读,并做批注。这里有很多不同于上个世纪的技巧。说三个 我常用的。
- 使用录音代替打字做笔记!尤其是给别人讲Paper的时候,使用录音的效果会更好!
- 对于部分外部配套图书或者好资料,及时拍照存档。
- 买一只电容笔 ,来在iPad上手写批注与笔记。
如下图所示:

神器1Notability与Zotero的配合,已经非常完美了,不过查找PDF的时候,还是略有不便。对于难以忍受这些不便的极端完美主义者来说,可以自己去编译或者购买开源的iPad APP:Zotpad,它的github网址是:https://github.com/mronkko/ZotPad
好的,现在云端Dropbox会自动同步多媒体格式的笔记成功。我们解压rtfd格式之后,打开文档看看,如下图所示:

哈哈,直接点击播放声音,声音、笔记都在一起了!接下去的扫尾工作,可以将文档以附件形式归到相应Zotero的条目下。
社交的Zotero
有很多需要拉人讨论或者实验室、课题组共享一批文献。则可以在Zotero里面,创建一个私密或者公开的群组。如下图所示:

两大辅助神器:Altmetric与Utopia
Altmetric
刚才这个办法,仅仅是自己实验室内部的文献共享。那么,如何知道全世界关于这篇文献的意见呢?Altmetric就是拿来干这个的!将这个页面的书签拖到Chrome菜单栏上即可。
http://www.altmetric.com/bookmarklet.php
然后,当你在网页上读到任何一篇文献,让我们 以 @Zwai 在《心智简报》中翻译的这篇文章Is working memory training effective? A meta-analytic review为例。它的原文地址是:http://www.ncbi.nlm.nih.gov/pubmed/22612437
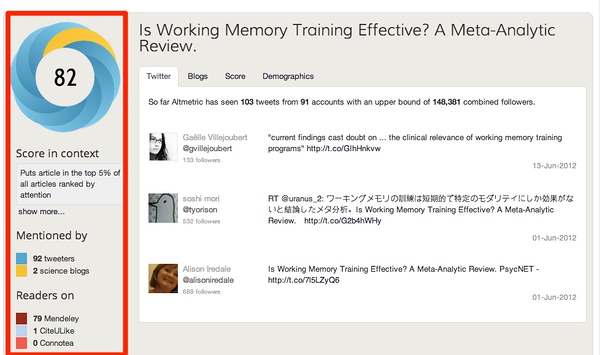
打开网页,然后点击Chrome书签栏上,我们在前一个步骤创建的书签:Altmetric。奇迹发生了!我们获得了一个分数,以及获得了全世界主要的媒体、博客、推特们对这篇文献的讨论。它是社交媒体中非常热门的一个讨论话题。(当然,在中国并不热门:D)如下图所示:

然后,我们查看详情,更酷了,获得了非常深入与专业的来源分析。如下图所示:
http://altmetric.com/details.php?citation_id=770688
我们了解到,有92人在推特上讨论过这篇文章,有2位博客作者写过对它的介绍。在研究社交网站上,有79位Mendeley读者下载与阅读过这篇文献,有1位CiteULike读者下载与阅读过这篇文献。

Utopia
但是,很多PDF文档,事先下载好了,我们一篇一篇这么去查它的社交媒体影响力,岂不是累死?专为研究2.0时代而生的Utopia来了!同样是免费、跨平台。下载地址是:
http://getutopia.com/download.php
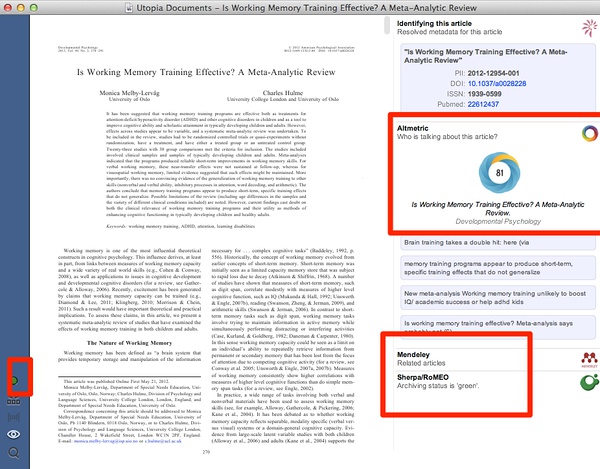
这是个专注PDF阅读的神器。由老友@鍾智敏wiswood介绍。utopia文档(以下简称utopia)是一款令人惊奇,免费、跨平台好软件,界面简洁优雅。它专注于学术PDF阅读,实现了什么?对PDF的笔记分享与数据加载!类似于kindle加载其他读者写过的批注!还可加载第三方数据,比如维基百科、生物化学数据等。同样,更酷的是,它的online模式,默认会将该篇PDF文档的社交媒体信息读取出来,比如上文altmetric分数。同样,不仅仅是altmetric分数,utopia还会调用大量第三方高质量信息源的API,读出它的授权信息等。
仍然以Is working memory training effective? A meta-analytic review这篇文献为例,我们下载过来,http://www.apa.org/pubs/journals/releases/dev-49-2-270.pdf
通过utopia打开:

当我们默认是online模式的时候,utopia这个PDF阅读器会自动加载它的altmetric分数等信息。
当然,utopia的功能不仅仅局限于此,它支持大量第三方高质量信息源,如它的入门文档描述一样:http://getutopia.com/quickstart.php
感兴趣的读者,可以去阅读utopia团队发表的学术论文:
http://getutopia.com/publications.php
目前,《生物化学杂志》已经使用它,通过与第三方命科学的数据的协作,让每一篇论文都变得动态起来。如何与Zotero配套使用,将utopia变为默认PDF阅读器即可。更进一步的做法则是,调用altmetric,整理文献。
mendeley与Zotero的同步
软件不是非此即彼的互斥关系。mendeley善于识别PDF元数据信息,大量处理PDF时,交给它好了。mendeley提供了Zotero同步功能。如下图所示:

小结
今天的信息日益海量,通过各类社会化过滤器,使得我们能够与同行保持更密切的联系,比如专注科学文献社交媒体影响力评估的altmetric等。同样,时代的变迁也正在诞生大量优秀的神器,如专注于平板笔记的神器1Notability与专注于学术PDF阅读的神器2[utopia]。这些神器,在以Zotero作为主文献库的配合之下,将发挥更强大的战斗力。
有友邻反映dropbox读出来的是凌乱的目录路径,比如一连串字符,导致在平板电脑上阅读不方便。
解决这一问题,请使用插件Zotfile。但是,该插件尚不支持Zotero4.0,请换回Zotero 3.0老版本。3.0下载地址是:http://www.zotero.org/support/3.0
然后再下载Zotfile插件,下载地址是:http://www.jlegewie.com/zotfile.html
下载好了,在Drobox目录下面,创建一个tablet目录,如下图所示:

然后安装好Zotfile插件。安装好了,重启Zotero,设置参数:

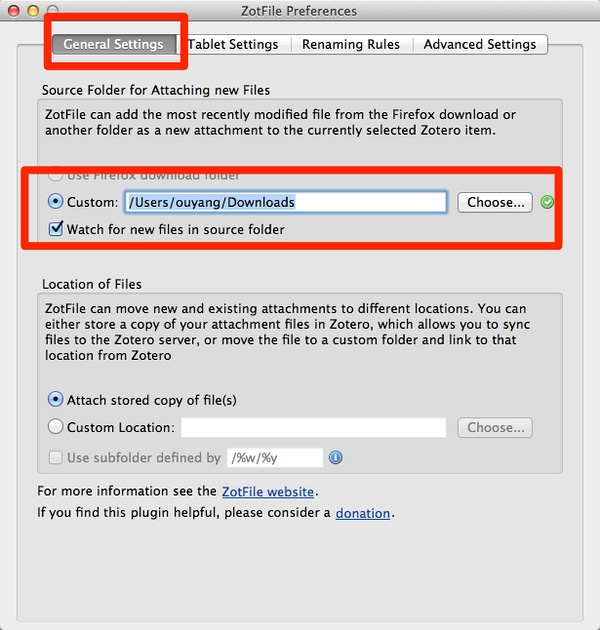
设置你日常下载pdf的路径,让它监视你的PDF下载文件夹:

然后关键步骤到了!设置平板电脑参数:

启动支持平板电脑的参数,设置之前创建的dropbox目录:
/Users/ouyang/Dropbox/zotero/tablet
好的。完成了。
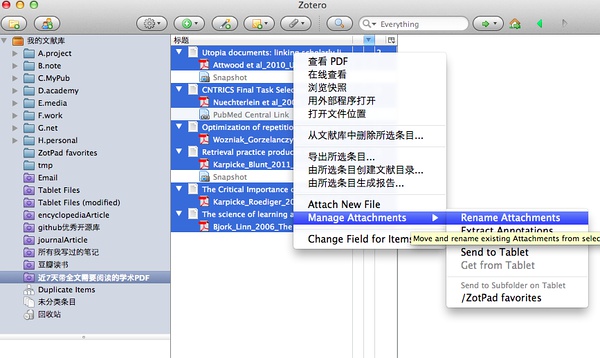
回到Zotero主界面。调出之前创建的搜索【近7天需要阅读的PDF】或者任意一个带PDF文档的目录,=》全选=》右键=》批量更改PDF文件,这样,非常漂亮的PDF文件名就出来了!比如:
Karpicke_Roediger_2008_The Critical Importance of Retrieval for Learning.pdf
这是作者名-发表年份-论文名的自动重命名。

同样,全选之后,发送到Tablets,就会将这些PDF文件发送到一个单独的tablets目录下面:

然后在iPad或者安卓平板里面,打开dropbox下面的tablets目录即可。使用[Notability]等之前介绍过的PDF批注软件,正常批注即可。
如下图所示:

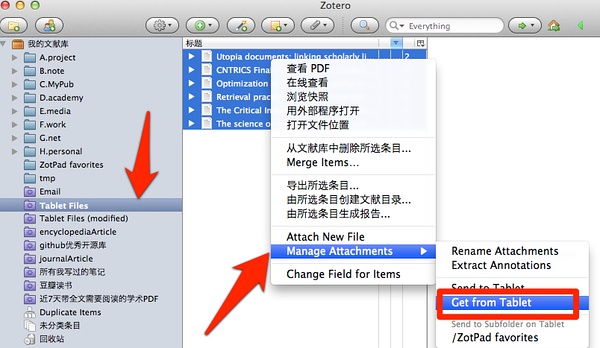
批注完了,可以在Zotero软件界面之后,取回所有PDF。如下图所示:

以上步骤的英文解说参见:http://www.columbia.edu/~jpl2136/zotfile.html#tablet
正好Dropbox中文版近日发布,祝大家使用愉快:D
之前写过四篇关于Zotero技巧的帖子。
- Zotero(1):文献管理软件Zotero基础及进阶示范
- Zotero(2):作为知识管理工具的Zotero
- Zotero(3):平板与社交:再谈研究辅助工具Zotero兼配套APP
- Zotero(4):Zotero之Zotfile插件的使用
在找这几篇旧文的朋友,可以去我的个人博客看看,存档在那里:http://t.cn/z8dHbTM 多数技巧还没过时。今天这篇帖子则侧重,如何打造一个半自动化的电子文献资料管理流程。这篇不讲基础安装、云同步等技巧,前面帖子已经讲得够多了。让我们开干吧,超详细,众多技巧汇合,请耐心看。
问题1:如何快速收藏电子书或者论文?
假设在豆瓣看了一本好书,如丹尼特新作【直觉泵】,网址如下:
点击浏览器右上角的Zotero图标,收藏即可:
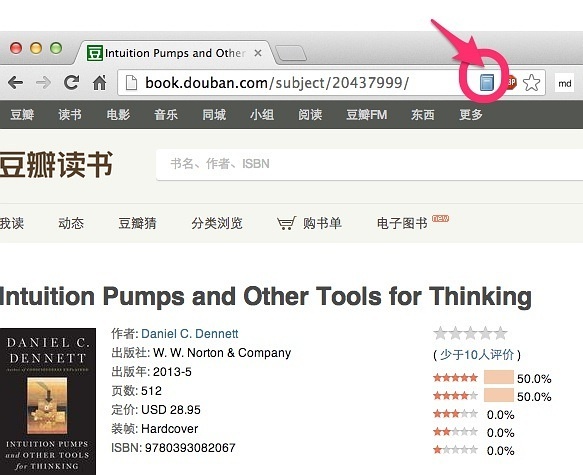
好了,打开Zotero,我们看到,该书已经保存在这里了。

同样,对于论文你也可以如此处理,参照老文章,建议多使用Google Scholar
问题2:如何标记文献的重要性?
步骤如下:
1、在丹尼特这本书的条目这里,创建一个【重要文献】类似标签;
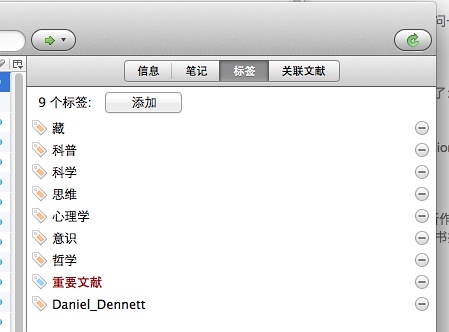
2、在界面的左下角,找到【重要文献】该标签,然后右键,对该标签指派颜色:
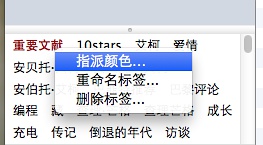
比如红色,同时会指派快捷键,如【1】如下图所示:
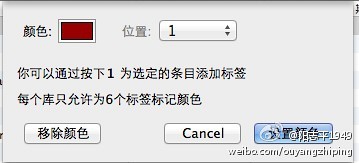
3、以上操作只需要执行一次。未来就很爽了,看到好文献,直接键盘按【1】就表示喜欢。最多可分配6个数字。比如,1表示非常重要文献,2表示比较重要文献,诸如此类。
问题3:怎么判断文献重要性?
我们怎么判断文献特别重要呢?有三个简单办法:
- 作者的重要性:比如【H指数】
- 文献的引用次数:比如【Google学术引用次数】
- 文献的学术社交媒体影响力,比如【altmetric分数】
以前的文章与我最近的微博,都谈过最后一个办法【altmetric分数】,这里就不详细说了。只说第一个与第二个办法:H指数与Google学术引用次数。先说第一个:H指数。
H指数是什么?如果人际关系混得不错,在30以上,一般在国内可以拿下学霸地位。超过50,凤毛麟角,属于普通老百姓要珍惜的大牛级别科学家。比如,施一公是60。
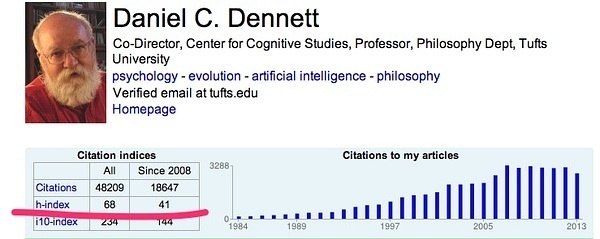
比如,丹尼特这位作者的H指数可以在这里查询:Daniel C. Dennett - Google Scholar Citations
我们发现他高达68,那么就表示这位作者非常重要:
我们对丹尼特这本书标记为很重要,那么,选中它,按个【1】就可以了,效果如下图所示:
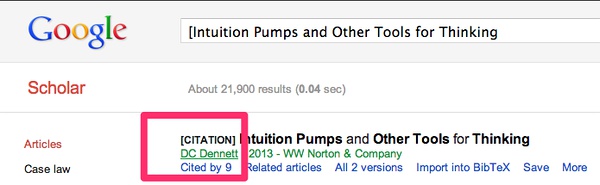
接下来,我们说说第二个简单办法,【Google学术引用次数】。当然,你可以去Google学术,查看被引次数,然后手动添加。比如,丹尼特这本书被引用9次:
不过,懒鬼可不是这思路。我们可以借助插件自动更新【Google学术引用次数】。
因为新读者可能是第一次接触Zotero插件安装,这里多解释几句如何安装插件。
1、打开Zotero的【插件】窗口,位置如下所示:
2、然后下载插件,比如该插件的下载地址是:
3、下载好了,回到Zotero的插件安装界面,如下图所示:
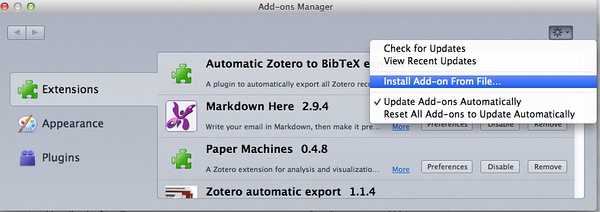
安装好了,如有必要,重启Zotero即可。
好的,继续回到丹尼特这本书。我们点击右键,更新一下引用即可。
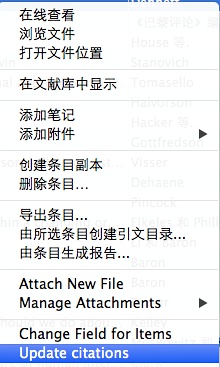
问题马上来了,更新完了,我们看条目的【引用次数】那里还是空的啊!老阳,这是怎么回事!
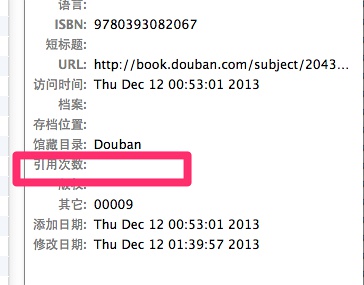
别急,这是该插件开发者为了避免将你条目自带的【引用次数】字段与【Google学术引用次数】冲突,所以,他将其保存在【其它】那个字段里面去了。怎么显示它?如下图所示:
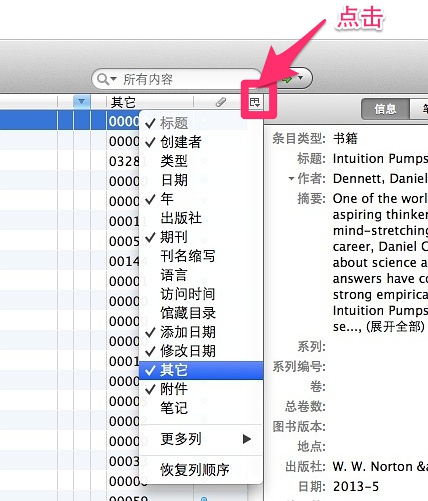
勾上它就可以了。我们再重新看一下界面,哇,【Google学术引用次数】真的有了!如下图所示:

丹尼特大神这本书因为才出版没多久,所以才被引9次。而另一位大神2004年出版的Culture, leadership, and organizations,因为属于某个流派开山之作,被引用了3281次。
因为zotero-scholar-citations这个插件是可以批量更新【Google学术引用次数】的。如此一来,我们标记论文、图书重要性,就更容易了。不过需要特别注意的是,Google学术本身为了防止机器人,做了限制,你一次别更新太多文献了,那样,将弹出一个窗口,Google需要你填入验证码,确定你不是机器人,才能继续更新。
问题4:怎样查找英文原版电子书?
说一下怎么查找英文原版书。
1、电子书检索:http://t.cn/zY3Vmkp
这几个网站可检索到70%网上曾出现过的;
2、私有数据库:如果是心理学,推荐APA的psycinfo数据库与MIT的cognet数据库,新书多半可查到;
3、国家图书馆的英文新书非常齐全,多半可复印到,同时可辅以各高校藏书;
4、亚马逊,尤其是kindle直接购买电子书。
问题5:如何保存电子书?
好的,丹尼特这本书,我们假设已经查到了电子书。但是,从网上下载的电子书,命名乱七八糟,不一定符合你的规律,同时,能否自动将下载的电子书导入到Zotero库中?
有,这就是我之前在:Zotero(4):Zotero之Zotfile插件的使用 中介绍过的Zotfile插件。
安装办法仍然同上一个插件一样,我们在它的官网找到插件下载:
http://www.jlegewie.com/zotfile.html
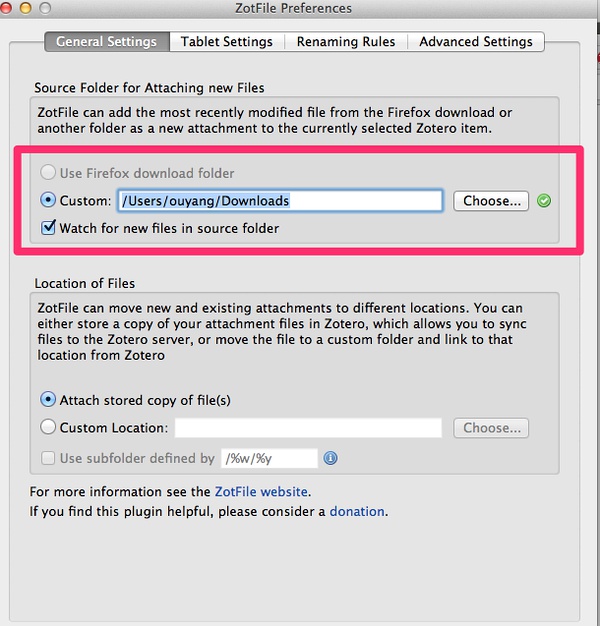
假设,我们平时从网上下载电子资料,都放在【download】目录下面,那么,在插件中心那里,设置Zotfile的常用目录是【download】目录。如下图所示:
继续:
完工!未来我们下载电子书时,就会自动导入。它的原理是这样的:
1、假设在Zotero中,我们的鼠标正选中了丹尼特这本书的条目。
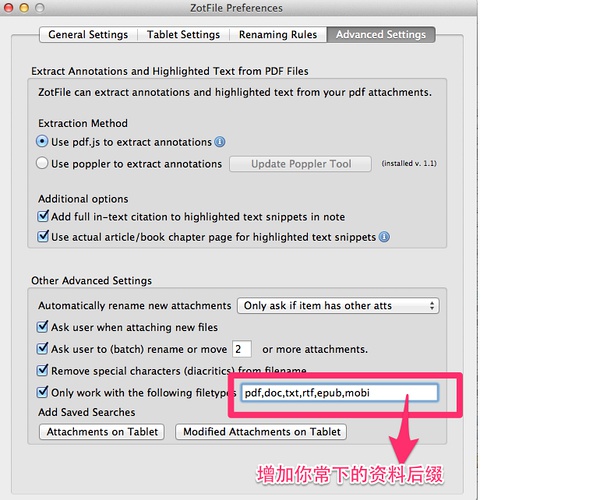
2、此时,我们通过浏览器,下载了这本书的电子版,保存在【download】目录下面。那么,插件Zotfile就会识别出来,并且默认认为这个电子文件是该条目的附件。然后自动导入过来。它默认支持pdf、doc、txt等格式,你也可以设置更多格式,如常用的epub、mobi格式,如下图所示:
3、同时,导入文件成功后,会自动将文件重命名为【作者_出版年份_文献标题】这种格式。当然,你不喜欢这种文件名格式,也可以在刚才那里自定义其它命名方法。
成功后,如下图所示:
以前那些乱七八糟的PDF怎么处理呢?我们可以将每本电子书拖到对应条目下面。然后批量重命名即可。如下图所示:
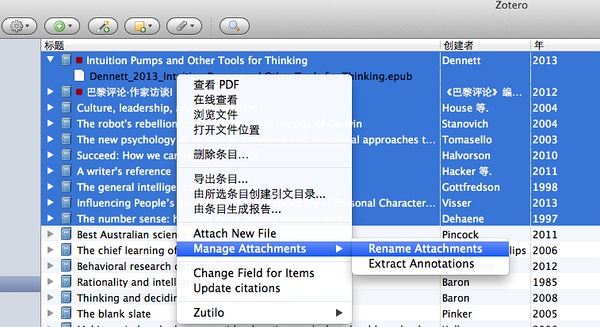
问题6:如何写笔记?
好了,收藏狂们一般非常乐意干前面5个步骤,却不太喜欢干这个步骤:读书与写笔记。
Zotero现已支持用Markdown格式写笔记,强!步骤如下,
1)在插件中心,安装Markdown here插件,http://t.cn/8kxA5bG
2)重启后,找到条目,然后新建一笔记,如下图所示:

我们开始用Markdown语法写笔记。这是笔记原文。
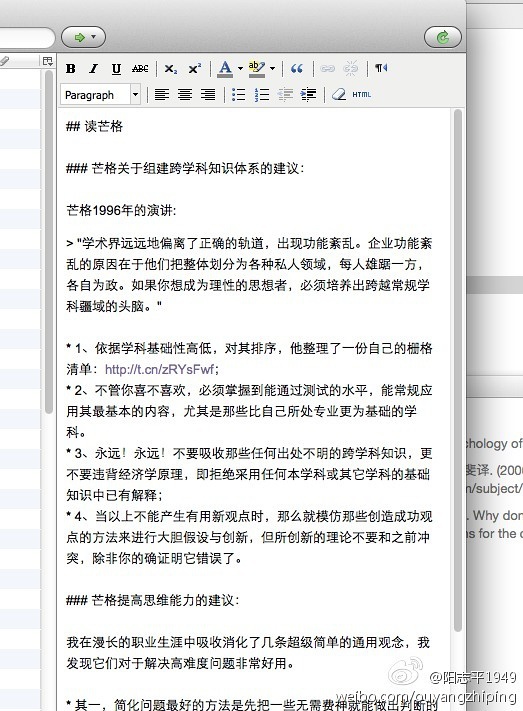
按下快捷键:【ctrl+alt+m】,你用Markdown写的笔记就生成为漂亮的文档了!下图是生成效果:

什么?你还在问:Markdown语法是什么?枉我推广这么久。。。
去读这里:Markdown在线写作速成
问题7:Zotero如何配合altmetric分数?
什么是altmetric分数?它可以查出在论文互引网站、推特、科学博客、专业科学媒体上对论文的议论等。 当然,仅限国外科学媒体。
Zotero如何配合使用?我之前的两篇老文章介绍比较详细了,
这里重点讲讲平板上,如iPad上如何配合使用。
科技发展真快,zotero配合altmetric分数,可以按照论文社交媒体影响力,来排序了。这样同行在看的重要论文一目了然了。如下图所示:
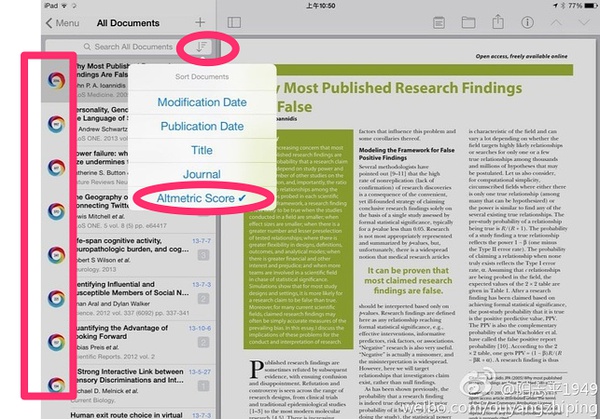
将文献按照altmetric分数排序即可。然后社交媒体影响越大的,就越排在前面。扫了一下今年我看的论文,同行热议的,集中在:
- 1、研究方法的讨论,第一篇就是;
- 2、计算社会科学类,如第二篇就是Facebook线索识别人格;
- 3、某个生理区域的突破;
- 4、纵向跟踪研究,如第五篇发现书呆子有利于保护认知老化。
问题8:看资料看晕了,怎么办?
有一种学问,叫做【科学计量学】,研究【科学的科学】,之前也写过很多文章介绍了。比如这篇:
其实,Zotero也可以完成类似任务。这就是我之前介绍过的papermachine插件。下载地址在这里:
How to Use Paper Machines | Paper Machines
对一个类别论文进行【文献可视化】分析,结果如下。先看词云(Word Cloud)的分析结果,如下图所示:

再看看Topic Modeling的分析结果。如下图所示:
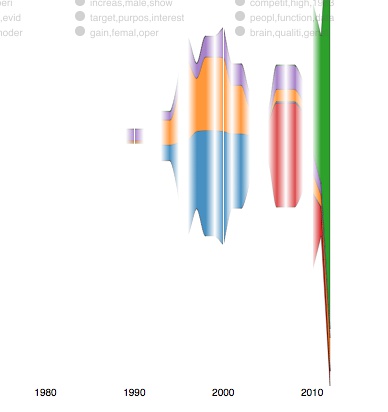
前者可以看出该子类论文关键词;后者可看出从1990到2010年,该研究领域随时间的动荡。当然,我选择的示范数据不好,并不能体现出其厉害之处。
一个不算遗憾的小提醒是,papermachine插件目前只支持英文等语种论文分析,另一个问题是,它对版本兼容性要求较高。
问题9:mendeley与 Zotero,哪个更好?
这又是一个读者老问我的问题,谁叫这个世界上,有一种叫做【选择障碍】的病。这么说吧,开源世界的发展速度快于你的想象。 mendeley 被商业公司收购后,很多拥抱开放科学理念的科学家,开始抵制mendeley了,转投Zotero怀抱。如这位:
昨晚帮大家,再次测试mendeley,看一下它最新进展如何,结果还是不得不放弃,安心用我的zotero。它的缺点有什么呢?
- 其一,对于文献量庞大到一定程度的人,程序崩溃太频繁;
- 其二,它的zotero整合功能,还是无法自动导入子文件夹;
- 其三,搜索全方位弱于zotero,在Zotero中,我可以任意定义诸如【豆瓣近7天看的书】,【30天前看的BBS这本刊物的论文】,以备复习使用,而mendeley难以做到;
- 其四,mendeley超过2g空间就收费。Zotero至少10g空间随便用。
- 其五,对于中国用户来说,mendeley还有个致命缺点,无法导入豆瓣读书记录与github的程序库;无法将笔记与论文区分开。这样,只能将其当做文献管理软件而非知识管理软件用。
贵阳小杨哥(http://blog.yesmryang.net/tags/Zotero/),也是忠实的开源软件Zotero推广者,在我的微博评论下,补充道:
Zotero早就可以把「附件」和「题录」分开放置了!附件放Dropbox/skydrive/百度盘什么的,20G不是问题!
小结
开源程序的发展速度往往超出人们想象。目前Zotero引领的开源引文格式项目——CSL,已经突破六千多期刊。以致商业科技出版公司的人不敢相信。每过一些日子,你又会发现一些好用的小技巧。隔一段时间,对天天用的软件,更新使用模式,是个好习惯。同时,开源程序总具备一种质朴的美。Zotero将电子书或PDF、笔记、引用文献三者放在一起,从下载电子书或PDF,到阅读、做标注、写笔记,再到引用,一条龙服务,非常方便。有特别不满意的地方,源代码公开了,自己修改就好了。
我们还可以自定义这些zotero搜索类别:【2013年看过的书】、【2013年看过的论文】与【2013年写过的读书笔记】、【2013年阅读的最重要的论文】或者【2013年同行评价最高的论文】。年底这么整理一下,温故而知新,也很有成就感:D
相关旧文
本文假设你已经详细阅读过前面五篇,对Zotero有一定基础了。
Q1. 如何批量抓取PDF文档,快速了解研究者重点
在前面的文章中,你应该学会一个重要技巧了,就是通过【google学术】,根据作者名字或者论文名字,搜索出论文全文,然后批量保存到Zotero中。
但是,现实生活中,还常常存在另一类需求。就是作者很慷慨地提供了自己所有论文的PDF文档,列在个人网站上,以备同行引用。
因为作者自己提供的文档往往清晰度更高、比【Google学术】中根据作者名字搜出来的更齐全一些。怎么批量下载,然后导入到Zotero中?让我们来举个例子。
APA今年的奖评刚出来了。每年这些奖项里面,【早期职业生涯贡献奖】 与 【杰出贡献奖】 参考价值不错,一个代表心理学未来,获奖者:http://t.cn/8kxCp3n 一个代表心理学过去,获奖者:http://t.cn/8kxCp3E
其中,Linda B. Smith很猛,近两年双丰收。才拿2013年侧重认知科学基础卓越贡献奖的David E. Rumelhart奖(现在火爆的深度学习大牛Hinton是第一个拿这个奖的),今年又拿 【杰出贡献奖】 。她的个人主页:http://t.cn/8kxphwG
我们就以她的论文为例。
步骤如下:
1、安装一个chrome的批量下载插件:
Chrome Web Store - DownloadAll
2、访问Linda B. Smith提供出版物的网页,她恰巧在自己的个人网站上,提供了PDF全文列表,网址如下:
Cognitive Development Lab - Indiana University. Bloomington
点击该插件,如下图所示:
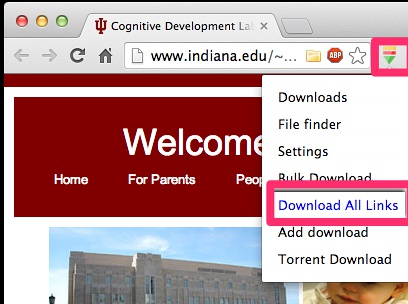
选择后缀为pdf,开始下载。如下图所示:
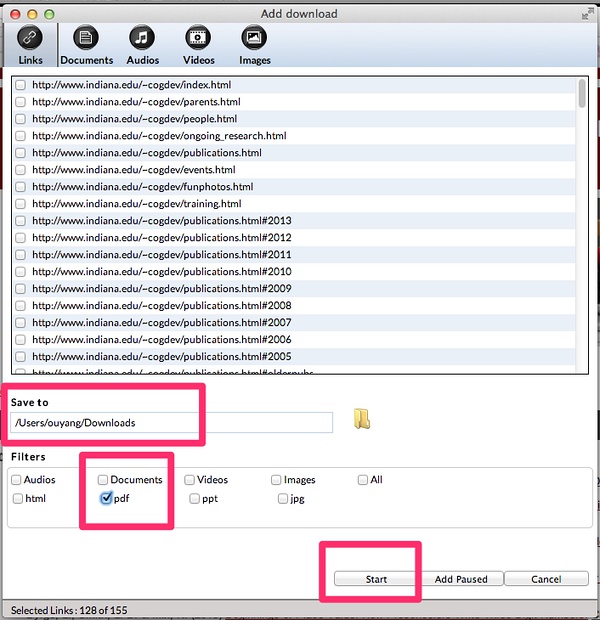
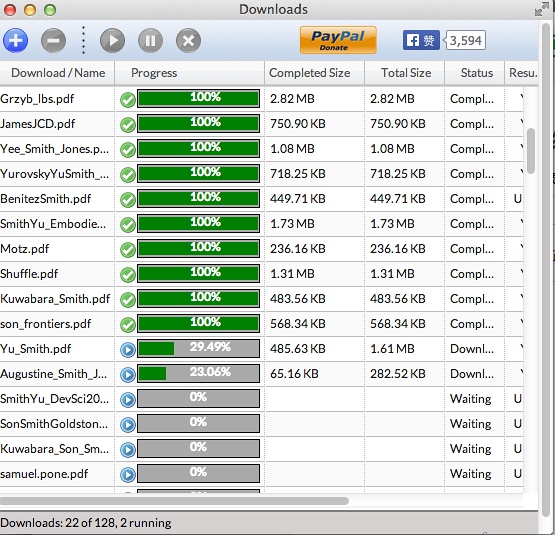
牛人发的论文就是多,一百多篇,咱们可以去喝杯咖啡,让它慢慢下载,如下图所示:
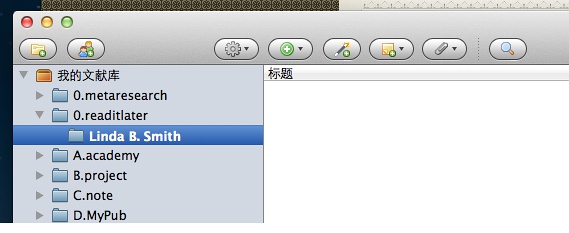
3、打开Zotero,新建一个目录,用于导入这些pdf,比如,我们建个目录,叫做:Linda B. Smith。
4、然后将下载的pdf文件,全部拖入到Linda B. Smith这个目录即可。如果你实在不知道怎么拖,就这么来,找到:【链接文件副本。。。】,然后按住shift键,选中所有下载的pdf文件。如下图所示:
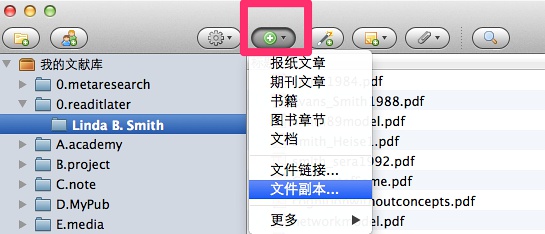
如果PDF文件太多,电脑内存较少,请注意别死机,可以考虑分批链接。
5、接下来,我们根据下载的PDF,批量生成文献信息,如下图所示,选中所有PDF文件,右键:
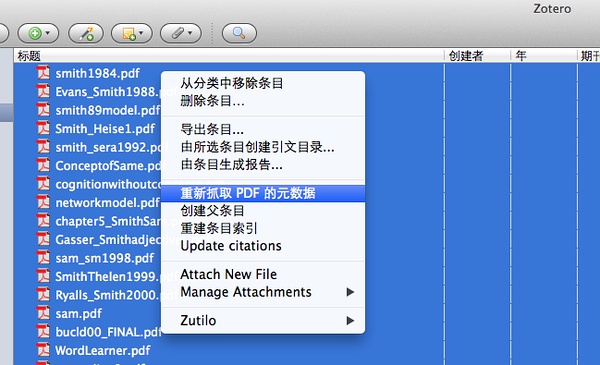
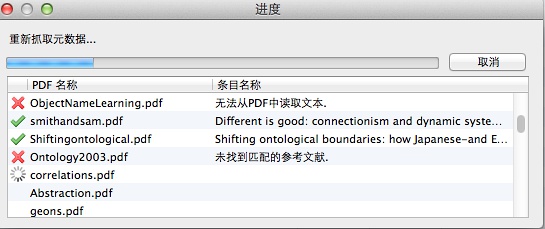
有些没找到文献信息的PDF,要么是年代过早,要么是版本保护问题,咱们先不管它。也请特别注意,一次别更新太多文献信息,【Google学术】目前有同一时间请求数量限制,50篇以内最好,超过后请稍候片刻。
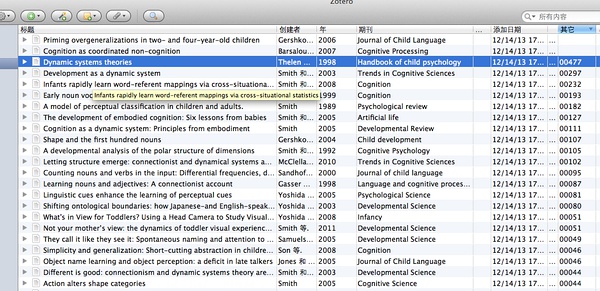
6、最后,看一下所有论文的【google学术引用次数】,按照【其它】字段排序。这样,我们就可以知道Linda B. Smith的核心论文是哪几篇了。
Q2. 如何建立自己的个性化知识库
今天,受我鼓吹,开始用Zotero的几位朋友,都在问我同一个问题:为什么不能保存国内某某网站、某某网站呢?
答:这是设计哲学的不同,它只默认抓取高质量信息,如google学术、science、经济学人、华尔街日报这些。 国内那些信息质量差的网站,不看也罢。
这是Zotero已支持的信息来源:http://t.cn/zTqrKc3
你可以自定义更多信息来源,或拍个网页快照来保存。如下图所示:
自定义信息类型与网页快照的区别是,网页快照不区分网页来源,也不进行个性化处理。无论来自什么网站,都统一是拍个快照。自定义信息类型,则可以进行更多精细加工处理。比如,将Zotero知识库列出什么菜谱、TED视频、问答。未来,你可以基于这个自定义信息类型,去进行更多的操作。你可以将它理解为一种对网上半结构化信息进行处理的手段。
在Zotero中,这个自定义信息类型,一般叫做:translators。有以下四种:
- Web translators:比如,抓取豆瓣图书,将其数据类型整理为book。这是一位开发者写好的:zotero/translators
- Import translators
- Export translators
- Search translators
第一种是最常用的。我们可以借助于Web translators,定义自己的TED视频库、菜谱库。。。只要你想得到,都可以处理。第一次定义成功后,未来,你再次访问时,直接网页收藏即可。
那么,如何自定义信息库呢?自定义Zotero抓取信息类型非常容易,无需太多编程知识,只需对github与js有点基础就可以了。 Zotero也提供了一个插件,参见该插件:http://t.cn/8k6CVsb 与该文档:[dev:translators [Zotero Documentation](http://www.zotero.org/support/dev/translators)
小结
本文介绍了两个Zotero实用技巧。一个是当研究者提供了所有出版物时,如何批量下载,以及根据批量下载后的PDF生成文献引用信息,继而根据【google学术引用次数】找出她最重要的论文;一个是,如何保存任意网页,并根据自己个性化需求,开发自定义的translators,从而打造一个个性化的知识库。#文献管理软件Zotero基础及进阶示范
我的文献管理软件使用历史极其悠久,先后是:
- Endnote Windows版:十多年前,一位师兄,如今的小牛,曾经用[Endnote]下载过十年的JPSP论文,然后一篇一篇批注,从那时起,文献管理软件给我留下了极其深刻的印象;
- 老友创业团队开发的[NoteExpress],当之无愧的国内Windows下文献管理No.1。因为太熟悉它的诞生与发展历程,所以它也是我使用年头最长的文献管理软件,积累的文献库好几G。
- Endnote Mac版:07、08年慢慢转到Mac下,不得不抛弃[NoteExpress]了。
在Mac下,先后试用与比较过[Papers2]与[mendeley]。但是因为种种原因,最终还是回到Zotero下。有感于国内对这么一款极其优秀的开源软件非常不了解,特别介绍它的入门与进阶知识。
注册Zotero新账号并下载
登陆https://www.zotero.org/user/register/,注册一个自己的Zotero账号,请特别记住,username会直接生成个性域名,别乱起,未来会有些不方便。
下载Zotero单机版,也就是Zotero Standalone。Mac、Windows等通用。
http://www.zotero.org/download/
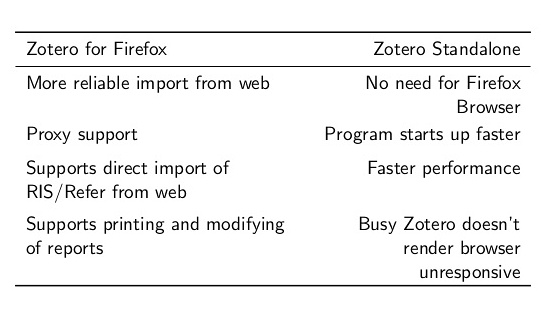
也可以下载firefox插件版,但是我更推荐单机版。两者的区别如下:
下载之后安装默认提示一路安装。
配置Zotero
打开Zotero,找到[首选项]或偏好:
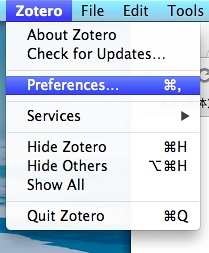
在同步一栏输入前面注册的账号,这样,文献库可以同步到[Zotero]官网。
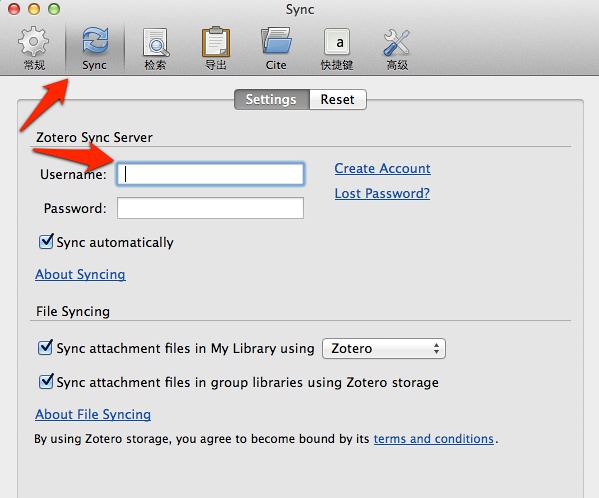
创建一个用来保存文献库的根目录,假设是:/users/ouyang/dev/zotero 继续配置:
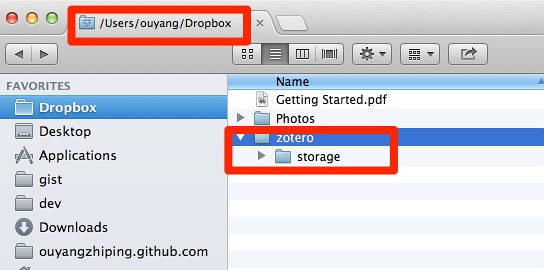
[Zotero]官网默认的存储空间有限,所以,我们需要一个小技巧,将文献库里面保存PDF文档的目录,分离开,放到[dropbox]目录下同步。回到刚才创建的:/users/ouyang/dev/zotero 目录,其中的storage目录是拿来保存PDF等文档的,将其剪切到[dropbox]目录下,如下图所示:
打开终端或shell,创建一个软连接,让[Zotero]认出该目录:
ln -s /users/ouyang/dropbox/zotero/storage /users/ouyang/dev/zotero/storage
回头看,/users/ouyang/dev/zotero 目录下多了一个软链接,表示成功了。
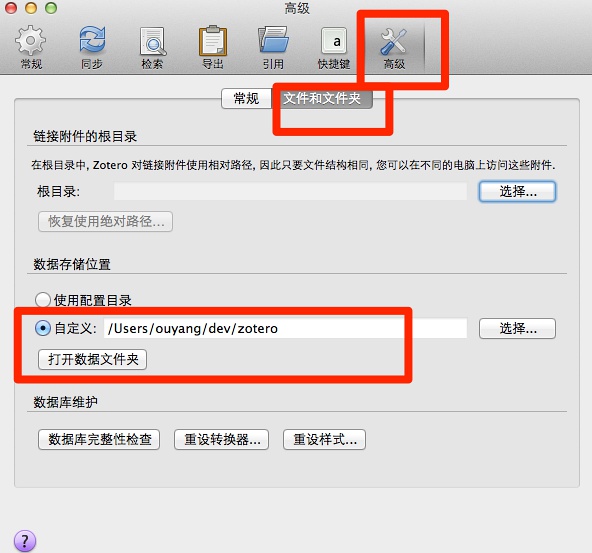
接下去,在配置这里安装pdf索引:
以及,将默认输出格式,更改为APA第六版:
导入第一篇文献
好了,准备工作做完了。现在,让我们导入第一篇文献。Zotero支持以下六种导入方法:
- 互联网自动识别:Web Translators (URL bar icon)
- 手动输入:Manual Input or Edit From a bibliographic
- 文件导入:format (RIS, BibTeX, MARC, etc.)
- 通过标示符增加:Add by identifier (DOI, ISBN, PMID)
- 通过PDF元数据识别:Add PDF then Retrieve Metadata
- 从网页识别:Get any Webpage with basic data
先让我们找找成就感,从最容易的开始。通过Web Translators,互联网自动识别。
打开豆瓣网站,随便找一本书,让我们以前一篇文章[心智十二宫]中的[我生活的种种模式]为例,它的豆瓣网页是:
http://book.douban.com/subject/1065156/
请特别注意,你的Chrome浏览器上会多出一个图书的标识!点击它,保存即可。
打开[Zotero]软件,我们会发现,之前鼠标定位的子类下面,会多出一个条目,如下图所示:
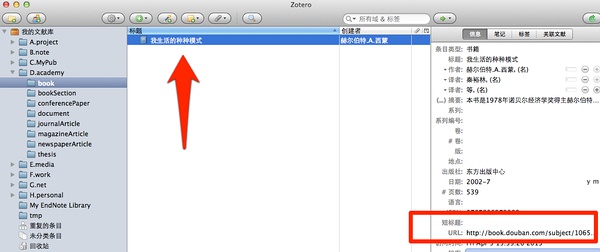
更有趣的是,[我生活的种种模式]这本书的豆瓣网址直接保存下来了,下次直接点击即可。这就是[Zotero]极其强大的Web Translators 功能,它可以根据世界上主要的信息资讯网站,生成相应的图标,比如,豆瓣的图书就是图书的小符号,维基百科则是维基类的小图标。更强大的是,一切你想保存资讯的网站,你可以定制Web Translators,然后保存在之前我们创建的根目录:
/users/ouyang/dev/zotero 下面的translators目录里面。如下图所示:
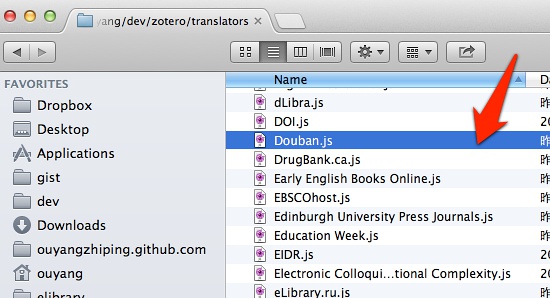
小提醒:如果没有多出这个图标,Web Translators 功能没有生效,是插件安装失误,请通过Chrome网上应用店,安装:Zotero Connector。
导入维基百科
通过集体智慧的协作,目前[Zotero]软件的Web Translators已经几乎支持世界上主要高质量资讯网站,如维基百科、Google学术。现在,让我们继续找点成就感,自动导入维基百科试试看。
学习一门新学科,常常需要知道学科中的牛人,维基百科的列表功能就是非常强大的资讯源。我们打开它的认知科学家列表,基本代表了功成名就的认知科学家们:
http://en.wikipedia.org/wiki/List_of_cognitive_scientists
我们会发现,这次图标与保存豆瓣的图书图标不一样了!哈哈,变成一个百科全书的图标了,如下图所示:
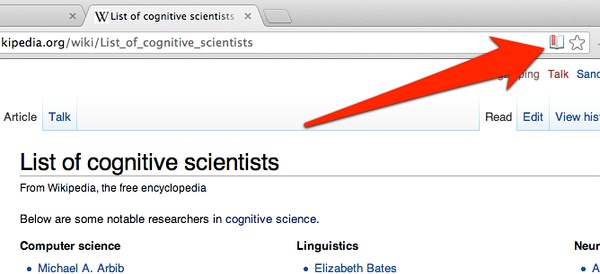
我们仍然点击保存,好的,文献库就有了!
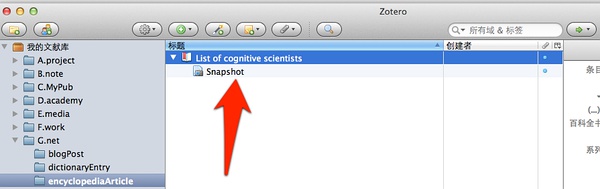
嗯?这次保存下来的为什么与上次的不太一样!多了个快照?点击看看!原来这是[Zotero]软件的另一个强大而贴心的功能,它自动将网页的快照拍摄下来了。这样,未来这个网页消失了,我们的资讯还没丢失!
导入Google学术
一次一次导入一篇,并不是学术研究时的常见现象。更常见的是,批量导入多篇。让我们以Google学术库为例。打开Google学术库,我们输入检索关键词,[netlogo],一个网络仿真常用软件。
http://scholar.google.com/scholar?q=netlogo&btnG=&hl=zh-CN&as_sdt=0%2C5
我们发现,这次浏览器的图标变成一个文件夹!这就意味着,有多篇文献识别出来,需要保存。
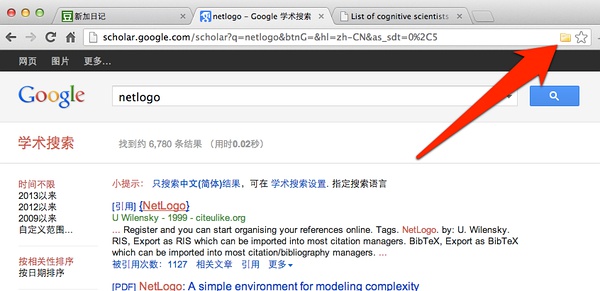
点击文件夹图标,然后弹出对话窗口,我们挑选一篇引用率排第一、带PDF文档的保存下来:
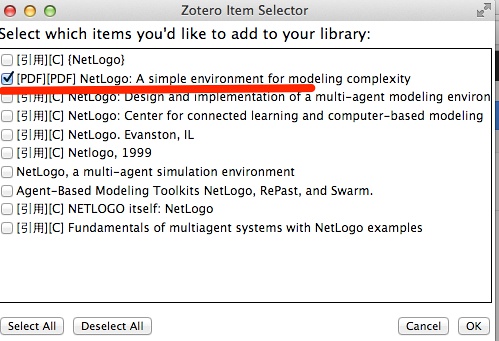
打开[Zotero]软件,我们怒了!作为一个开源软件,它为什么能这么贴心!Google学术里面带PDF文档,刚才弹出窗口提示有PDF字眼的,它连关联PDF也关联起来了!如下图所示:
通过标示符增加
总有一些文献,google学术检索不出来(虽然,这个概率越来越低)。这个时候,需要我们手动添加。
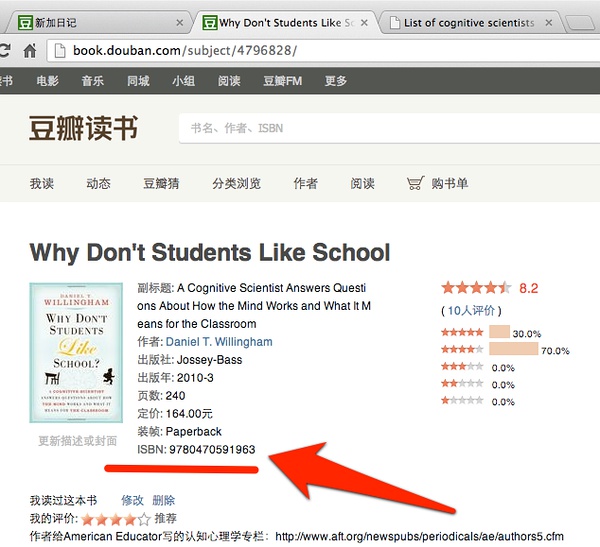
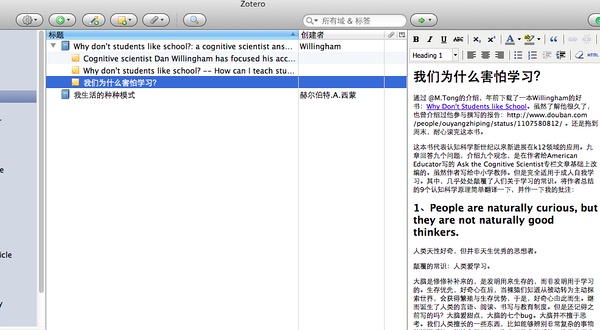
让我们以前一篇文章[我们为什么害怕学习]为例,通过豆瓣,找到[Why Don’t Students like School]这本书的ISBN是:9780470591963。如下图所示:
我们启动[Zotero]软件,点击通过标示符增加的按钮:
输入ISBN:9780470591963。即可添加成功,如下图所示:
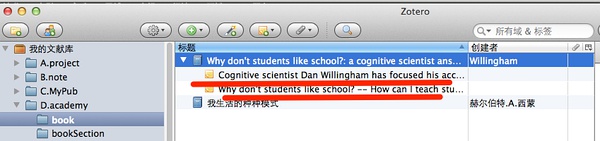
这次我们继续怒了!开源软件的贴心程度已经超出我们想象,这次保存下来的图书信息,多了什么呢!原来,多了两条笔记,来自出版商的介绍!
好的,接下去,我将我写的笔记保存进来。选中图书名字,点击右键:添加笔记。一般用户可以直接在这里写笔记。
如果是Markdown与Mou用户,则不要在这里直接写笔记,代码会额外混乱,点击html选项:
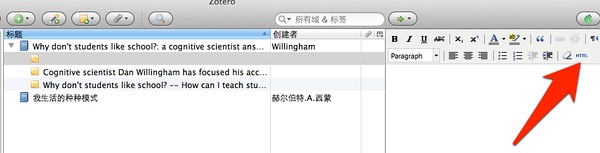
将Mou生成的html内容复制过去:
效果如下图所示,非常漂亮的笔记出来了!
小提醒:不过这么整理还是略微有些麻烦,笔者正在想办法,将[Zotero]与[Mou]、[Evernote]的配合更智能化。
导入Endnote数据库
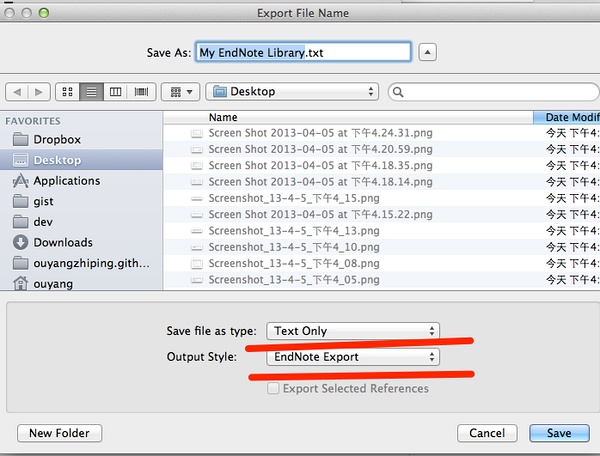
好的,我们有大量的文献是使用其它文献管理软件管理的,怎么导入?以最流行、最常用的[Endnote]为例。选择File=>Export,如下图所示,记得一定要将导出风格选为:Endnote Export:
然后,导出的文本文件,直接导入到[Zotero]中即可,更复杂的导入方法,可以参考各类教程。
导入PDF文档
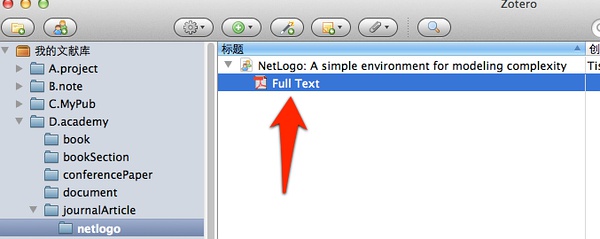
有不少之前下载好的PDF文献,尤其是一些本来是从学术数据库下载的文献,它们支持PDF元数据功能,这样就非常省事,可以直接拖到[Zotero]中来,然后会自动将其文献信息识别出来。
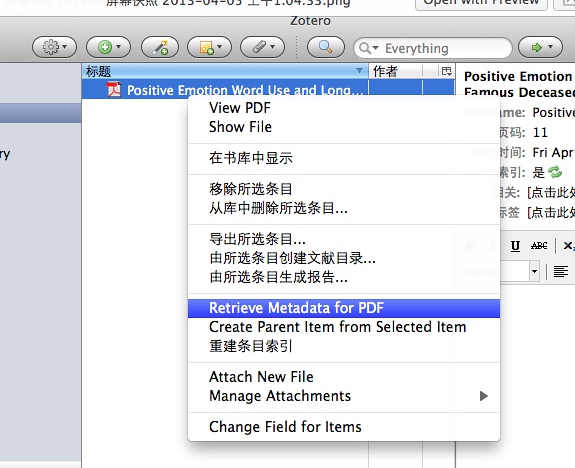
如下图所示,我们将一个PDF文档拖到自己的项目文件夹中来,然后选择右键:[抓取PDF的元数据],
就自动根据PDF元数据生成相关文献信息了:
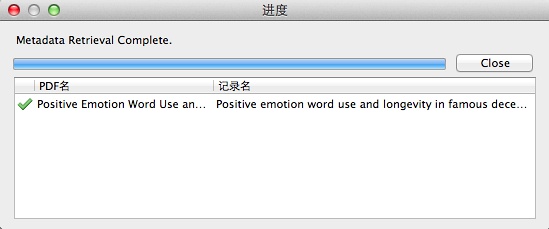
Zotero进阶示例:文献可视化
在上面这个导入例子中,我们用的是同事的一篇学位论文的参考文献库,研究的主题是青少年与社会网络分析。我们尝试对这些文献进行可视化分析。
首先,需要安装插件papermachines,下载xpi文件,http://chrisjr.github.com/papermachines/,文件地址是:http://www.papermachines.org/download/papermachines-0.4.4.xpi
我们通过[Zotero]的插件安装,如下图所示:
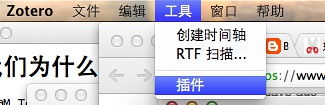
然后点击:Install Add-on from File…
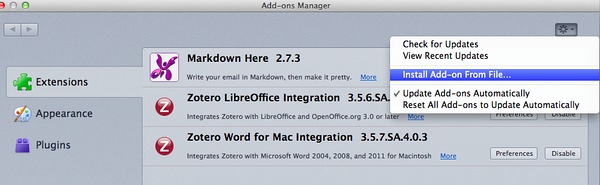
找到之前下载的xpi文件,安装好,重启[Zotero]。
然后选中我们要进行文献分析的库,如下图所示:
第一次运行,需要继续重启[Zotero],重启之后,就好了,点击各类,查看文献可视化的结果:

这是以标签云形式对一百多篇文献进行分析的结果,接下去,我们可以换个视图:

我们可以清晰地发现,我同事的学位论文中,引用的文献聚焦在:青少年吸烟、社会网络、同辈群体、关系等主题上。
Zotero更多资源
Zotero还有更多进阶玩法,在这里不展开讲了。各位感兴趣的敬请查阅资料:
入门教程
- zotero中文快速入门:http://www.zotero.org/support/zh/quick_start_guide
- Zotero中文入门介绍:http://www.zotero.org/support/_media/zotero_miniguide.pdf
- 台湾中央研究院计算中心关于Zotero的介绍:http://ascc.sinica.edu.tw/iascc/articals.php?_section=2.4&_op=?articalID:3934
- MIT图书馆的教程:http://libguides.mit.edu/zotero
- Washington University St. Louis: http://libguides.wustl.edu/zotero
- Zotero入门介绍:http://www.slideshare.net/adam3smith/intro-zotero *你为什么需要Zotero:其中关于六类人的漫画描述,极其生动。
- 研究生2.0关于Zotero的介绍
- 老杨与他本科同学写的Zotero介绍
核心插件
- Zotero插件大全
- zotero插件集合
- Papermachine
- Zotfile
- Multi-Lingual Zotero
- Qnotero
- Translator testing
- Zotero隐藏的偏好:http://www.zotero.org/support/preferences/hidden_preferences
- RTF Scan
版式风格在线可视编辑
整合工具
- Omeka : Zotero开发学校的另一个项目
- editorsnotes
- Zotero开发机构的其他项目:http://chnm.gmu.edu/research-and-tools/
移动支持
http://www.zotero.org/blog/zotero-apps-go-mobile/
小结
与其说[Zotero]是一个文献管理软件,不如说是一个知识管理平台。选择开源软件,就是选择一个生态链,这是与商业软件,如[Papers2]、[mendeley]或[Endnote]非常不一样的地方。
在前文文献管理软件Zotero基础及进阶示范中,主要介绍了作为文献管理工具、学术工具的Zotero。今天说说作为一个超级强大的知识管理工具的Zotero,比如书签管理、网页收藏、分类知识体系、快速学习等。
Tag体系的问题
这么多年,我认识的朋友,除非是超级勤奋的,一般正常人,很少有坚持使用tag系统成功的。它 存在什么问题?
- 在收藏的时候,无法坚持输入多个tag系统,有的多,有的少,甚至有的没有,导致最后凌乱;
- 当事先非常规整的Tag系统,一旦由于对某个Tag的描述改变,导致很多前面的Tag更改不及时;
- 需要记忆与复习的时候,Tag提取不便,因为Tag系统总会随着时间崩溃
简而言之,Tag系统的本质并不适合分类,而是【印象】系统,这才是Tag系统的本意。但是,太多的人将其当做分类工具在使用,最后导致得不偿失,付出的精力往往得不到相应的产出。人类的最佳知识表征结构是什么?
我提过多次的MIT认知科学家Josh(今年将来中国做邀请演讲)发表在pnas的论文中,比较了抽象知识的不同表征结构,如星形结构、聚类结构、环形结构等等,最终还是意识到,人类的最佳知识结构是树形结构。只有树形结构,才是最符合人类认知特点的一种结构,从树的上一层到下一层,是具备唯一通道,便于大脑将知识从记忆底层快速提取出来,符合人类大脑是个认知吝啬鬼的特点;树又是兼具横向扩展与纵向扩展能力的最优雅的结构。所以,儿童学习词汇时,最初是将物体进行扁平互斥的划分并对应到不同名称,当他们意识到,以树形结构来学习时,他们的认知开始大幅度发展。这种神秘的树形结构不仅仅影响到儿童早期的认知发展,在科学界,也处处可以看到神秘之树的身影,如门捷列夫的元素周期表开创近代化学;卡尔·冯·林奈使用树形结构创立了对自然世界的基本分类法。
Tag系统与树形结构相反,它实质上是非常违背人们学习与记忆提取的规律的。尤其当Tag更多是Tag,而不是树形结构的时候。它是个云形结构,会随着时间变迁而动荡。记忆恰巧需要的不是这类时间动荡。所以,太多人对Tag系统进行了种种改良,这种改良本质上,都是在放弃Tag自身,使用了主从类的,更贴近树形结构的改良。
Zotero的分类
作为对Tag系统的改良。在Zotero中,我们不推荐将Tag作为分类使用,而更多当做【印象】使用!请记住,Tag始终会随着时间而动荡甚至走向崩溃!所以,更重要的是,你当时当下对该文档的【印象】,而不是【分类】!
那么,如何更好分类?
- 以基本属性作为分类,基本属性是你可以很快归类的,不太会随时间动荡的;
- 再使用搜索代替随时间动荡的内容;
- 不再将Tag作为【分类】属性;而是当下【印象】工具。
如下图所示:
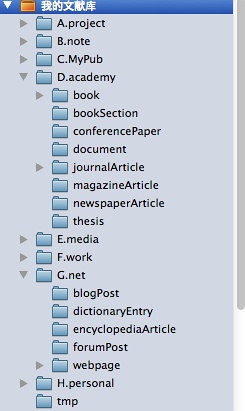
作为知识管理工具的Zotero示例
Zotero提供了一个非常强大的自定义搜索功能。类似于自动归类的文件夹。以下试举几例。
本周带全文需要阅读的学术论文PDF
点击:我的文献库,右键,新建搜索。如下图所示:
创建条件,如下图所示:
github优秀开源库收藏
豆瓣好书精选
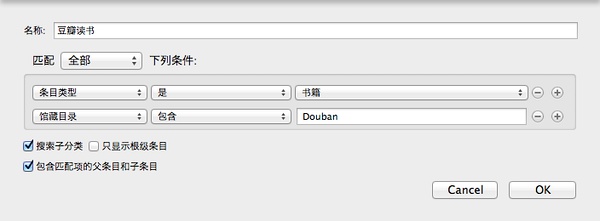
诸如此类不等。总之,可以尽情发挥想象力,定制出各类自动化的搜索分类。进一步,有熟悉js脚本的朋友,完全可以打开根目录,自定义自己的条目类型,如github、如微博。
事实上,大量的条目类型,已经由全世界网友提供了并且编写好了各类脚本,如推特、如维基百科、如readability、如Google图书、如Google博客。参见:
https://github.com/zotero/translators
如果自己撰写,可参考文档:
http://niche-canada.org/member-projects/zotero-guide/chapter1.html http://www.huangwei.me/blog/2011/01/06/write_zotero_translator/
作为快速学习的Zotero
维基百科是最佳的入门知识首选,Zotero可以创建知识的收藏时间线,如下图所示:
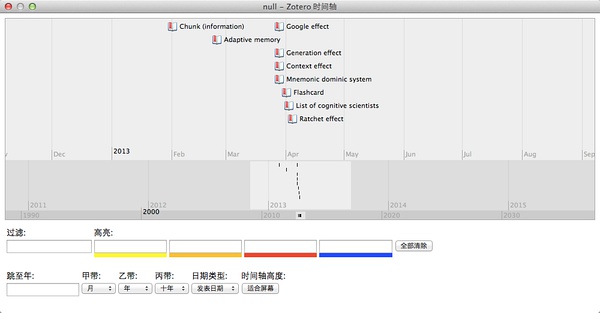
全文搜索的改进
Zotero由于是西方开源者开发,对中文、全文检索能力有时候不如Evernote等,如何改进?
由于Zotero是条目存储与附件相互分分离的。这么一来,只要使用你的桌面搜索工具,将Zotero的存储目录,即storage目录,加入到相应偏好里面。那么,你可以轻而易举拥有更强大、更快捷地,对你所有存储的网页快照、文献的全文检索。
在Windows下,可以使用Google桌面搜索;在Mac下,则自带的spotlight已经支持。如下图所示:
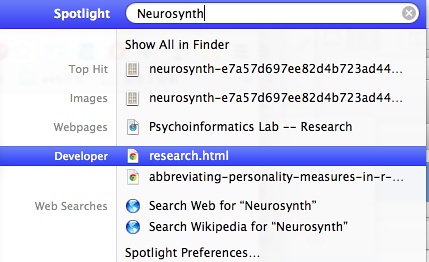
打开research.html页面一看,这就是保存在我们本地的网页快照:
file://localhost/Users/ouyang/Dropbox/zotero/storage/3PHJNDJE/research.html
然后打开Zotero,输入存储中的唯一标示符:3PHJNDJE。如下图所示,这样就非常快地借助超级强大的第三方全文检索工具,定位到Zotero中的内容了:

进一步,因为Zotero完全开源,包括同步去向,也可以搭建自己的同步服务器,在同步服务器上使用elasticsearch等搭建自己的超强全文检索库。
继续小白文风格,多图,高手慎入。很多亲朋好友们,都是卡在上手工具的那么几个关键小步骤。导致完全回避好的方法与工具,使用上个世纪的研究理念干苦力活。
人有时会念旧,十多年前,互联网可不是今天这样子。那时,我们谈论R语言、数据挖掘与文献管理,我们在谈论什么?昨晚,偶尔翻出当年担任版主的统计论坛:百岛潮统计论坛,时光如水,百岛潮当年单纯的气质已默默成为每人青春回忆中美好的一部分。
如今这个时代,知识看似垂手可得,研究日益变为职业与市场交易,研究的技术也跟随演化。继续前两天话题,将研究辅助工具再次说透彻点。这次侧重社交与移动。
移动的Zotero
以iPad的Safari为例,安卓的Chrome步骤大同小异。说说如何给Safari增加保存到Zotero文献库的选项。
步骤1:随便选一个页面,将它加入到Safari书签。如下图所示:

步骤2,打开iPad的设置,找到Safari,如下图所示,将【总是显示书签栏】给选为【on】。
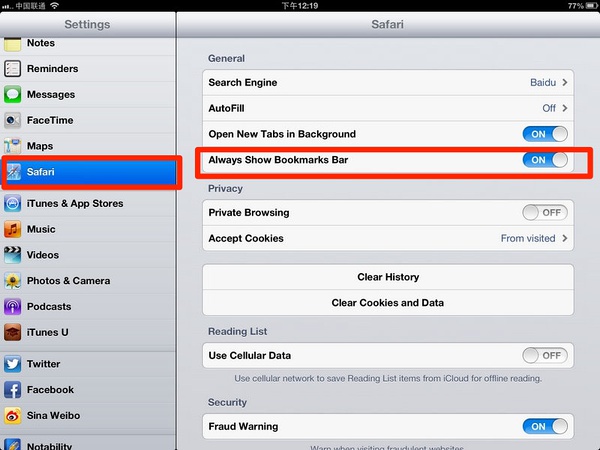
步骤3,打开iPad的Safari,然后触摸书签,再触摸【书签栏】,如下图所示:
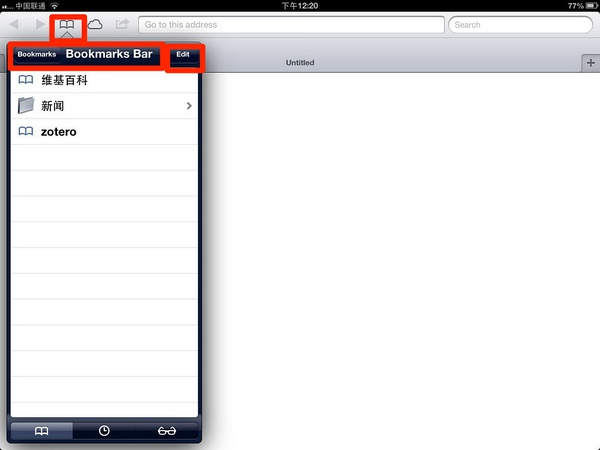
步骤4:好的,关键点到了!将之前在步骤1保存的Zotero,点击编辑,将网址更改为Zotero书签的内容。从这里复制:
http://www.zotero.org/downloadbookmarklet
如下图所示:
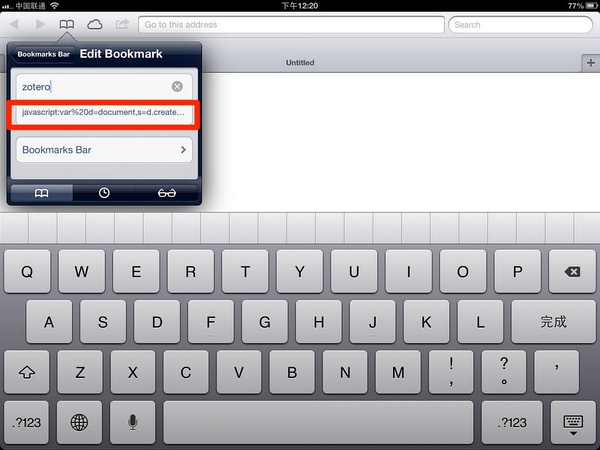
复制之后,效果如图:
步骤5:好的,大功告成,在平板上的Zotero.org网站,登陆一下你的账号,记住选择记住密码。然后随便挑选个论文库或者豆瓣读书试试看,我们会发现成功保存到云端的文献库中了。
平板的Zotero
一般习惯用Kindle读电子书,读PDF还是习惯平板设备。主要是批注速度、阅读速度较快。以下以iPad为例。同样,Zotero也支持安卓设备。
先从神器1Notability讲起。
Notability是一个好评如潮的PDF阅读与批注APP。如何与Zotero配合?关键点在第一篇文中的小技巧,将Zotero的条目与存储相互分离。Zotero的数据库仅仅用于保存条目等;而Dropbox用于保存PDF、网页快照等。
这么一来,通过Notability自带的与Dropbox自动同步的功能,就可以非常愉快与轻松地使用手指或者触控笔手写笔记。
步骤如下,
步骤1:购买并安装Notability
它非常物美价廉。安装后打开。
步骤2:在dropbox下面的zotero目录创建note目录
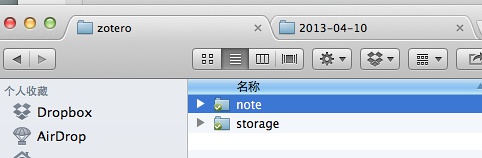
请记住!在老文文献管理软件Zotero基础及进阶示范 第一步建立的Dropbox下面的Zotero新建一个笔记目录!这是用来存放自动同步的笔记的,与存放PDF、电子书、网页快照的storage目录平级!如下图所示:
步骤3:设置Dropbox自动同步
回到Notability的设置里面,继续在import dropbox里面设置。如下图所示,选择设置:
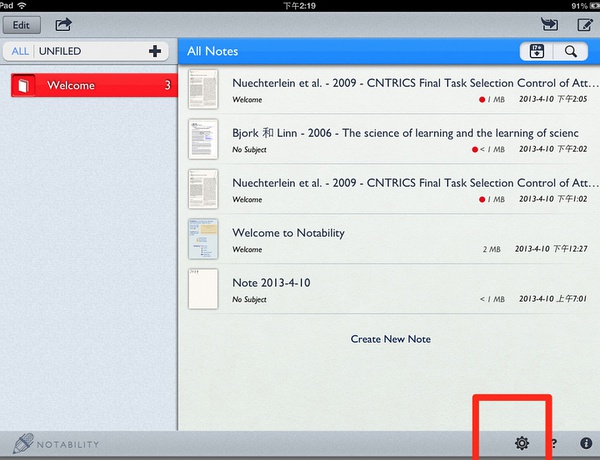
打开之后,选择自动同步选项:
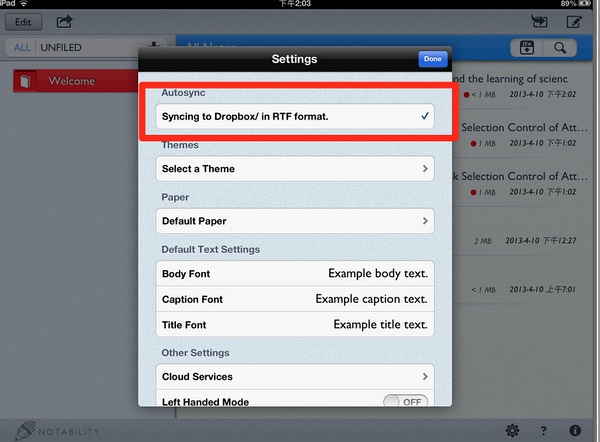
一步一步往下设置,选择Dropbox。
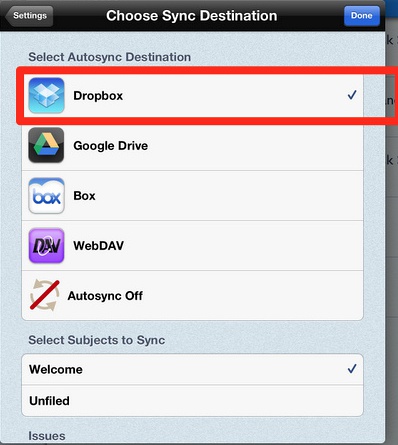
这是个比较关键的步骤,未来很多技巧会用到这个路径。所以,请务必选择刚才步骤2的[note]目录。
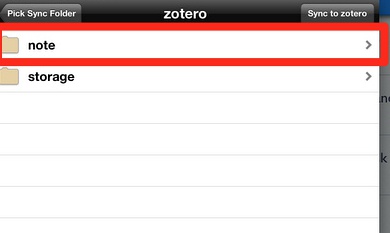
接下去,选择同步格式了。又是个关键步骤,一般建议选择rtfd格式。这是富文档格式,这样才能够直接保存录音、图片等。
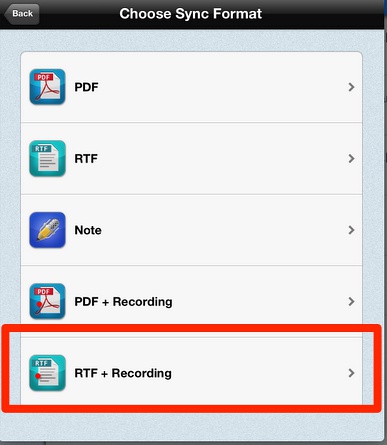
步骤4:导入Zotero里面保存的PDF文档,并写批注
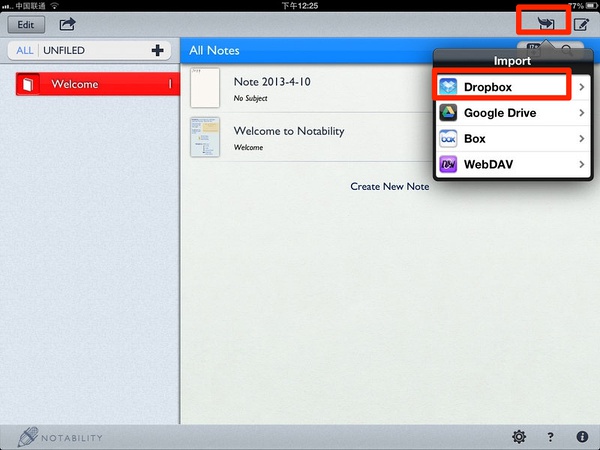
好的,大功告成。现在点击import,然后导入dropbox=>storage目录下面的pdf即可。如下图所示:
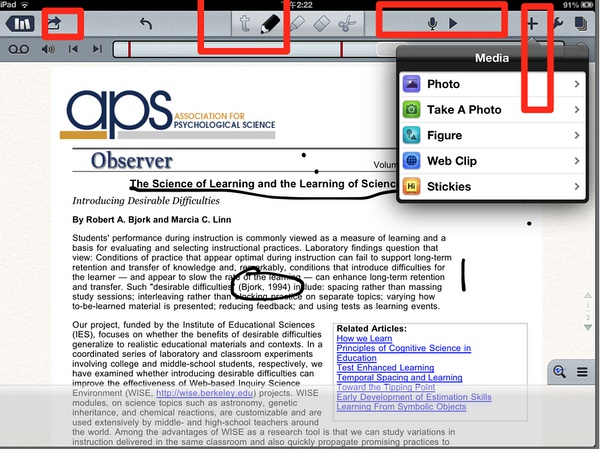
导入时,会询问你是否创建新笔记,选择是即可。打开pdf,开始阅读,并做批注。这里有很多不同于上个世纪的技巧。说三个 我常用的。
- 使用录音代替打字做笔记!尤其是给别人讲Paper的时候,使用录音的效果会更好!
- 对于部分外部配套图书或者好资料,及时拍照存档。
- 买一只电容笔 ,来在iPad上手写批注与笔记。
如下图所示:
神器1Notability与Zotero的配合,已经非常完美了,不过查找PDF的时候,还是略有不便。对于难以忍受这些不便的极端完美主义者来说,可以自己去编译或者购买开源的iPad APP:Zotpad,它的github网址是:https://github.com/mronkko/ZotPad
好的,现在云端Dropbox会自动同步多媒体格式的笔记成功。我们解压rtfd格式之后,打开文档看看,如下图所示:
哈哈,直接点击播放声音,声音、笔记都在一起了!接下去的扫尾工作,可以将文档以附件形式归到相应Zotero的条目下。
社交的Zotero
有很多需要拉人讨论或者实验室、课题组共享一批文献。则可以在Zotero里面,创建一个私密或者公开的群组。如下图所示:
两大辅助神器:Altmetric与Utopia
Altmetric
刚才这个办法,仅仅是自己实验室内部的文献共享。那么,如何知道全世界关于这篇文献的意见呢?Altmetric就是拿来干这个的!将这个页面的书签拖到Chrome菜单栏上即可。
http://www.altmetric.com/bookmarklet.php
然后,当你在网页上读到任何一篇文献,让我们 以 @Zwai 在《心智简报》中翻译的这篇文章Is working memory training effective? A meta-analytic review为例。它的原文地址是:http://www.ncbi.nlm.nih.gov/pubmed/22612437
打开网页,然后点击Chrome书签栏上,我们在前一个步骤创建的书签:Altmetric。奇迹发生了!我们获得了一个分数,以及获得了全世界主要的媒体、博客、推特们对这篇文献的讨论。它是社交媒体中非常热门的一个讨论话题。(当然,在中国并不热门:D)如下图所示:

然后,我们查看详情,更酷了,获得了非常深入与专业的来源分析。如下图所示:
http://altmetric.com/details.php?citation_id=770688
我们了解到,有92人在推特上讨论过这篇文章,有2位博客作者写过对它的介绍。在研究社交网站上,有79位Mendeley读者下载与阅读过这篇文献,有1位CiteULike读者下载与阅读过这篇文献。
Utopia
但是,很多PDF文档,事先下载好了,我们一篇一篇这么去查它的社交媒体影响力,岂不是累死?专为研究2.0时代而生的Utopia来了!同样是免费、跨平台。下载地址是:
http://getutopia.com/download.php
这是个专注PDF阅读的神器。由老友@鍾智敏wiswood介绍。utopia文档(以下简称utopia)是一款令人惊奇,免费、跨平台好软件,界面简洁优雅。它专注于学术PDF阅读,实现了什么?对PDF的笔记分享与数据加载!类似于kindle加载其他读者写过的批注!还可加载第三方数据,比如维基百科、生物化学数据等。同样,更酷的是,它的online模式,默认会将该篇PDF文档的社交媒体信息读取出来,比如上文altmetric分数。同样,不仅仅是altmetric分数,utopia还会调用大量第三方高质量信息源的API,读出它的授权信息等。
仍然以Is working memory training effective? A meta-analytic review这篇文献为例,我们下载过来,http://www.apa.org/pubs/journals/releases/dev-49-2-270.pdf
通过utopia打开:
当我们默认是online模式的时候,utopia这个PDF阅读器会自动加载它的altmetric分数等信息。
当然,utopia的功能不仅仅局限于此,它支持大量第三方高质量信息源,如它的入门文档描述一样:http://getutopia.com/quickstart.php
感兴趣的读者,可以去阅读utopia团队发表的学术论文:
http://getutopia.com/publications.php
目前,《生物化学杂志》已经使用它,通过与第三方命科学的数据的协作,让每一篇论文都变得动态起来。如何与Zotero配套使用,将utopia变为默认PDF阅读器即可。更进一步的做法则是,调用altmetric,整理文献。
mendeley与Zotero的同步
软件不是非此即彼的互斥关系。mendeley善于识别PDF元数据信息,大量处理PDF时,交给它好了。mendeley提供了Zotero同步功能。如下图所示:
小结
今天的信息日益海量,通过各类社会化过滤器,使得我们能够与同行保持更密切的联系,比如专注科学文献社交媒体影响力评估的altmetric等。同样,时代的变迁也正在诞生大量优秀的神器,如专注于平板笔记的神器1Notability与专注于学术PDF阅读的神器2[utopia]。这些神器,在以Zotero作为主文献库的配合之下,将发挥更强大的战斗力。
有友邻反映dropbox读出来的是凌乱的目录路径,比如一连串字符,导致在平板电脑上阅读不方便。
解决这一问题,请使用插件Zotfile。但是,该插件尚不支持Zotero4.0,请换回Zotero 3.0老版本。3.0下载地址是:http://www.zotero.org/support/3.0
然后再下载Zotfile插件,下载地址是:http://www.jlegewie.com/zotfile.html
下载好了,在Drobox目录下面,创建一个tablet目录,如下图所示:
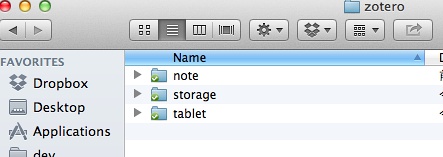
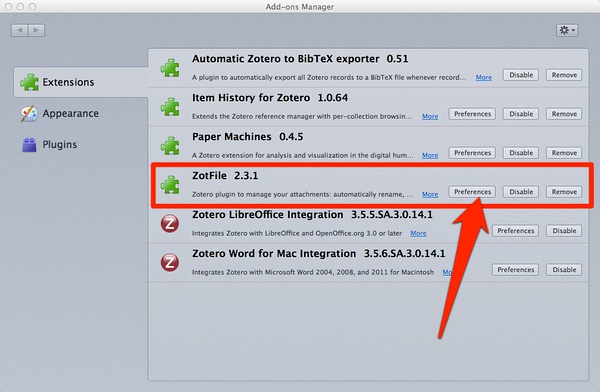
然后安装好Zotfile插件。安装好了,重启Zotero,设置参数:
设置你日常下载pdf的路径,让它监视你的PDF下载文件夹:
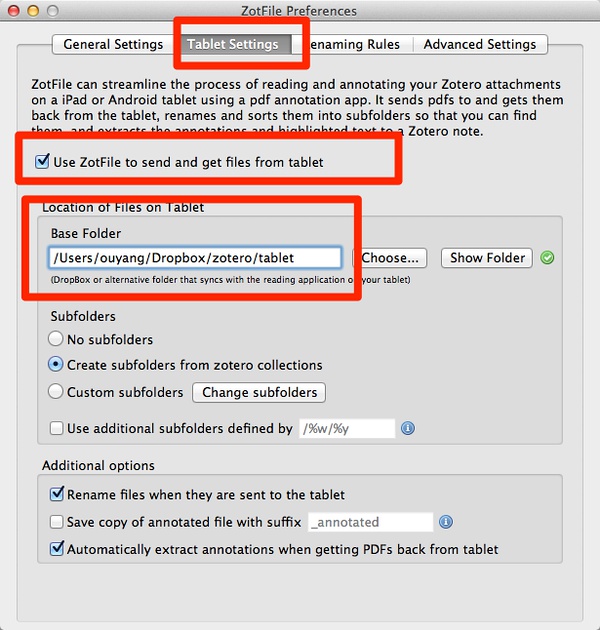
然后关键步骤到了!设置平板电脑参数:
启动支持平板电脑的参数,设置之前创建的dropbox目录:
/Users/ouyang/Dropbox/zotero/tablet
好的。完成了。
回到Zotero主界面。调出之前创建的搜索【近7天需要阅读的PDF】或者任意一个带PDF文档的目录,=》全选=》右键=》批量更改PDF文件,这样,非常漂亮的PDF文件名就出来了!比如:
Karpicke_Roediger_2008_The Critical Importance of Retrieval for Learning.pdf
这是作者名-发表年份-论文名的自动重命名。
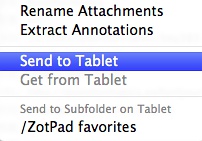
同样,全选之后,发送到Tablets,就会将这些PDF文件发送到一个单独的tablets目录下面:
然后在iPad或者安卓平板里面,打开dropbox下面的tablets目录即可。使用[Notability]等之前介绍过的PDF批注软件,正常批注即可。
如下图所示:
批注完了,可以在Zotero软件界面之后,取回所有PDF。如下图所示:
以上步骤的英文解说参见:http://www.columbia.edu/~jpl2136/zotfile.html#tablet
正好Dropbox中文版近日发布,祝大家使用愉快:D
之前写过四篇关于Zotero技巧的帖子。
- Zotero(1):文献管理软件Zotero基础及进阶示范
- Zotero(2):作为知识管理工具的Zotero
- Zotero(3):平板与社交:再谈研究辅助工具Zotero兼配套APP
- Zotero(4):Zotero之Zotfile插件的使用
在找这几篇旧文的朋友,可以去我的个人博客看看,存档在那里:http://t.cn/z8dHbTM 多数技巧还没过时。今天这篇帖子则侧重,如何打造一个半自动化的电子文献资料管理流程。这篇不讲基础安装、云同步等技巧,前面帖子已经讲得够多了。让我们开干吧,超详细,众多技巧汇合,请耐心看。
问题1:如何快速收藏电子书或者论文?
假设在豆瓣看了一本好书,如丹尼特新作【直觉泵】,网址如下:
点击浏览器右上角的Zotero图标,收藏即可:
好了,打开Zotero,我们看到,该书已经保存在这里了。
同样,对于论文你也可以如此处理,参照老文章,建议多使用Google Scholar
问题2:如何标记文献的重要性?
步骤如下:
1、在丹尼特这本书的条目这里,创建一个【重要文献】类似标签;
2、在界面的左下角,找到【重要文献】该标签,然后右键,对该标签指派颜色:
比如红色,同时会指派快捷键,如【1】如下图所示:
3、以上操作只需要执行一次。未来就很爽了,看到好文献,直接键盘按【1】就表示喜欢。最多可分配6个数字。比如,1表示非常重要文献,2表示比较重要文献,诸如此类。
问题3:怎么判断文献重要性?
我们怎么判断文献特别重要呢?有三个简单办法:
- 作者的重要性:比如【H指数】
- 文献的引用次数:比如【Google学术引用次数】
- 文献的学术社交媒体影响力,比如【altmetric分数】
以前的文章与我最近的微博,都谈过最后一个办法【altmetric分数】,这里就不详细说了。只说第一个与第二个办法:H指数与Google学术引用次数。先说第一个:H指数。
H指数是什么?如果人际关系混得不错,在30以上,一般在国内可以拿下学霸地位。超过50,凤毛麟角,属于普通老百姓要珍惜的大牛级别科学家。比如,施一公是60。
比如,丹尼特这位作者的H指数可以在这里查询:Daniel C. Dennett - Google Scholar Citations
我们发现他高达68,那么就表示这位作者非常重要:
我们对丹尼特这本书标记为很重要,那么,选中它,按个【1】就可以了,效果如下图所示:
接下来,我们说说第二个简单办法,【Google学术引用次数】。当然,你可以去Google学术,查看被引次数,然后手动添加。比如,丹尼特这本书被引用9次:
不过,懒鬼可不是这思路。我们可以借助插件自动更新【Google学术引用次数】。
因为新读者可能是第一次接触Zotero插件安装,这里多解释几句如何安装插件。
1、打开Zotero的【插件】窗口,位置如下所示:
2、然后下载插件,比如该插件的下载地址是:
3、下载好了,回到Zotero的插件安装界面,如下图所示:
安装好了,如有必要,重启Zotero即可。
好的,继续回到丹尼特这本书。我们点击右键,更新一下引用即可。
问题马上来了,更新完了,我们看条目的【引用次数】那里还是空的啊!老阳,这是怎么回事!
别急,这是该插件开发者为了避免将你条目自带的【引用次数】字段与【Google学术引用次数】冲突,所以,他将其保存在【其它】那个字段里面去了。怎么显示它?如下图所示:
勾上它就可以了。我们再重新看一下界面,哇,【Google学术引用次数】真的有了!如下图所示:
丹尼特大神这本书因为才出版没多久,所以才被引9次。而另一位大神2004年出版的Culture, leadership, and organizations,因为属于某个流派开山之作,被引用了3281次。
因为zotero-scholar-citations这个插件是可以批量更新【Google学术引用次数】的。如此一来,我们标记论文、图书重要性,就更容易了。不过需要特别注意的是,Google学术本身为了防止机器人,做了限制,你一次别更新太多文献了,那样,将弹出一个窗口,Google需要你填入验证码,确定你不是机器人,才能继续更新。
问题4:怎样查找英文原版电子书?
说一下怎么查找英文原版书。
1、电子书检索:http://t.cn/zY3Vmkp
这几个网站可检索到70%网上曾出现过的;
2、私有数据库:如果是心理学,推荐APA的psycinfo数据库与MIT的cognet数据库,新书多半可查到;
3、国家图书馆的英文新书非常齐全,多半可复印到,同时可辅以各高校藏书;
4、亚马逊,尤其是kindle直接购买电子书。
问题5:如何保存电子书?
好的,丹尼特这本书,我们假设已经查到了电子书。但是,从网上下载的电子书,命名乱七八糟,不一定符合你的规律,同时,能否自动将下载的电子书导入到Zotero库中?
有,这就是我之前在:Zotero(4):Zotero之Zotfile插件的使用 中介绍过的Zotfile插件。
安装办法仍然同上一个插件一样,我们在它的官网找到插件下载:
http://www.jlegewie.com/zotfile.html
假设,我们平时从网上下载电子资料,都放在【download】目录下面,那么,在插件中心那里,设置Zotfile的常用目录是【download】目录。如下图所示:
继续:
完工!未来我们下载电子书时,就会自动导入。它的原理是这样的:
1、假设在Zotero中,我们的鼠标正选中了丹尼特这本书的条目。
2、此时,我们通过浏览器,下载了这本书的电子版,保存在【download】目录下面。那么,插件Zotfile就会识别出来,并且默认认为这个电子文件是该条目的附件。然后自动导入过来。它默认支持pdf、doc、txt等格式,你也可以设置更多格式,如常用的epub、mobi格式,如下图所示:
3、同时,导入文件成功后,会自动将文件重命名为【作者_出版年份_文献标题】这种格式。当然,你不喜欢这种文件名格式,也可以在刚才那里自定义其它命名方法。
成功后,如下图所示:
以前那些乱七八糟的PDF怎么处理呢?我们可以将每本电子书拖到对应条目下面。然后批量重命名即可。如下图所示:
问题6:如何写笔记?
好了,收藏狂们一般非常乐意干前面5个步骤,却不太喜欢干这个步骤:读书与写笔记。
Zotero现已支持用Markdown格式写笔记,强!步骤如下,
1)在插件中心,安装Markdown here插件,http://t.cn/8kxA5bG
2)重启后,找到条目,然后新建一笔记,如下图所示:
我们开始用Markdown语法写笔记。这是笔记原文。
按下快捷键:【ctrl+alt+m】,你用Markdown写的笔记就生成为漂亮的文档了!下图是生成效果:
什么?你还在问:Markdown语法是什么?枉我推广这么久。。。
去读这里:Markdown在线写作速成
问题7:Zotero如何配合altmetric分数?
什么是altmetric分数?它可以查出在论文互引网站、推特、科学博客、专业科学媒体上对论文的议论等。 当然,仅限国外科学媒体。
Zotero如何配合使用?我之前的两篇老文章介绍比较详细了,
这里重点讲讲平板上,如iPad上如何配合使用。
科技发展真快,zotero配合altmetric分数,可以按照论文社交媒体影响力,来排序了。这样同行在看的重要论文一目了然了。如下图所示:
将文献按照altmetric分数排序即可。然后社交媒体影响越大的,就越排在前面。扫了一下今年我看的论文,同行热议的,集中在:
- 1、研究方法的讨论,第一篇就是;
- 2、计算社会科学类,如第二篇就是Facebook线索识别人格;
- 3、某个生理区域的突破;
- 4、纵向跟踪研究,如第五篇发现书呆子有利于保护认知老化。
问题8:看资料看晕了,怎么办?
有一种学问,叫做【科学计量学】,研究【科学的科学】,之前也写过很多文章介绍了。比如这篇:
其实,Zotero也可以完成类似任务。这就是我之前介绍过的papermachine插件。下载地址在这里:
How to Use Paper Machines | Paper Machines
对一个类别论文进行【文献可视化】分析,结果如下。先看词云(Word Cloud)的分析结果,如下图所示:
再看看Topic Modeling的分析结果。如下图所示:
前者可以看出该子类论文关键词;后者可看出从1990到2010年,该研究领域随时间的动荡。当然,我选择的示范数据不好,并不能体现出其厉害之处。
一个不算遗憾的小提醒是,papermachine插件目前只支持英文等语种论文分析,另一个问题是,它对版本兼容性要求较高。
问题9:mendeley与 Zotero,哪个更好?
这又是一个读者老问我的问题,谁叫这个世界上,有一种叫做【选择障碍】的病。这么说吧,开源世界的发展速度快于你的想象。 mendeley 被商业公司收购后,很多拥抱开放科学理念的科学家,开始抵制mendeley了,转投Zotero怀抱。如这位:
昨晚帮大家,再次测试mendeley,看一下它最新进展如何,结果还是不得不放弃,安心用我的zotero。它的缺点有什么呢?
- 其一,对于文献量庞大到一定程度的人,程序崩溃太频繁;
- 其二,它的zotero整合功能,还是无法自动导入子文件夹;
- 其三,搜索全方位弱于zotero,在Zotero中,我可以任意定义诸如【豆瓣近7天看的书】,【30天前看的BBS这本刊物的论文】,以备复习使用,而mendeley难以做到;
- 其四,mendeley超过2g空间就收费。Zotero至少10g空间随便用。
- 其五,对于中国用户来说,mendeley还有个致命缺点,无法导入豆瓣读书记录与github的程序库;无法将笔记与论文区分开。这样,只能将其当做文献管理软件而非知识管理软件用。
贵阳小杨哥(http://blog.yesmryang.net/tags/Zotero/),也是忠实的开源软件Zotero推广者,在我的微博评论下,补充道:
Zotero早就可以把「附件」和「题录」分开放置了!附件放Dropbox/skydrive/百度盘什么的,20G不是问题!
小结
开源程序的发展速度往往超出人们想象。目前Zotero引领的开源引文格式项目——CSL,已经突破六千多期刊。以致商业科技出版公司的人不敢相信。每过一些日子,你又会发现一些好用的小技巧。隔一段时间,对天天用的软件,更新使用模式,是个好习惯。同时,开源程序总具备一种质朴的美。Zotero将电子书或PDF、笔记、引用文献三者放在一起,从下载电子书或PDF,到阅读、做标注、写笔记,再到引用,一条龙服务,非常方便。有特别不满意的地方,源代码公开了,自己修改就好了。
我们还可以自定义这些zotero搜索类别:【2013年看过的书】、【2013年看过的论文】与【2013年写过的读书笔记】、【2013年阅读的最重要的论文】或者【2013年同行评价最高的论文】。年底这么整理一下,温故而知新,也很有成就感:D
相关旧文
本文假设你已经详细阅读过前面五篇,对Zotero有一定基础了。
Q1. 如何批量抓取PDF文档,快速了解研究者重点
在前面的文章中,你应该学会一个重要技巧了,就是通过【google学术】,根据作者名字或者论文名字,搜索出论文全文,然后批量保存到Zotero中。
但是,现实生活中,还常常存在另一类需求。就是作者很慷慨地提供了自己所有论文的PDF文档,列在个人网站上,以备同行引用。
因为作者自己提供的文档往往清晰度更高、比【Google学术】中根据作者名字搜出来的更齐全一些。怎么批量下载,然后导入到Zotero中?让我们来举个例子。
APA今年的奖评刚出来了。每年这些奖项里面,【早期职业生涯贡献奖】 与 【杰出贡献奖】 参考价值不错,一个代表心理学未来,获奖者:http://t.cn/8kxCp3n 一个代表心理学过去,获奖者:http://t.cn/8kxCp3E
其中,Linda B. Smith很猛,近两年双丰收。才拿2013年侧重认知科学基础卓越贡献奖的David E. Rumelhart奖(现在火爆的深度学习大牛Hinton是第一个拿这个奖的),今年又拿 【杰出贡献奖】 。她的个人主页:http://t.cn/8kxphwG
我们就以她的论文为例。
步骤如下:
1、安装一个chrome的批量下载插件:
Chrome Web Store - DownloadAll
2、访问Linda B. Smith提供出版物的网页,她恰巧在自己的个人网站上,提供了PDF全文列表,网址如下:
Cognitive Development Lab - Indiana University. Bloomington
点击该插件,如下图所示:
选择后缀为pdf,开始下载。如下图所示:
牛人发的论文就是多,一百多篇,咱们可以去喝杯咖啡,让它慢慢下载,如下图所示:
3、打开Zotero,新建一个目录,用于导入这些pdf,比如,我们建个目录,叫做:Linda B. Smith。
4、然后将下载的pdf文件,全部拖入到Linda B. Smith这个目录即可。如果你实在不知道怎么拖,就这么来,找到:【链接文件副本。。。】,然后按住shift键,选中所有下载的pdf文件。如下图所示:
如果PDF文件太多,电脑内存较少,请注意别死机,可以考虑分批链接。
5、接下来,我们根据下载的PDF,批量生成文献信息,如下图所示,选中所有PDF文件,右键:
有些没找到文献信息的PDF,要么是年代过早,要么是版本保护问题,咱们先不管它。也请特别注意,一次别更新太多文献信息,【Google学术】目前有同一时间请求数量限制,50篇以内最好,超过后请稍候片刻。
6、最后,看一下所有论文的【google学术引用次数】,按照【其它】字段排序。这样,我们就可以知道Linda B. Smith的核心论文是哪几篇了。
Q2. 如何建立自己的个性化知识库
今天,受我鼓吹,开始用Zotero的几位朋友,都在问我同一个问题:为什么不能保存国内某某网站、某某网站呢?
答:这是设计哲学的不同,它只默认抓取高质量信息,如google学术、science、经济学人、华尔街日报这些。 国内那些信息质量差的网站,不看也罢。
这是Zotero已支持的信息来源:http://t.cn/zTqrKc3
你可以自定义更多信息来源,或拍个网页快照来保存。如下图所示:
自定义信息类型与网页快照的区别是,网页快照不区分网页来源,也不进行个性化处理。无论来自什么网站,都统一是拍个快照。自定义信息类型,则可以进行更多精细加工处理。比如,将Zotero知识库列出什么菜谱、TED视频、问答。未来,你可以基于这个自定义信息类型,去进行更多的操作。你可以将它理解为一种对网上半结构化信息进行处理的手段。
在Zotero中,这个自定义信息类型,一般叫做:translators。有以下四种:
- Web translators:比如,抓取豆瓣图书,将其数据类型整理为book。这是一位开发者写好的:zotero/translators
- Import translators
- Export translators
- Search translators
第一种是最常用的。我们可以借助于Web translators,定义自己的TED视频库、菜谱库。。。只要你想得到,都可以处理。第一次定义成功后,未来,你再次访问时,直接网页收藏即可。
那么,如何自定义信息库呢?自定义Zotero抓取信息类型非常容易,无需太多编程知识,只需对github与js有点基础就可以了。 Zotero也提供了一个插件,参见该插件:http://t.cn/8k6CVsb 与该文档:[dev:translators [Zotero Documentation](http://www.zotero.org/support/dev/translators)
小结
本文介绍了两个Zotero实用技巧。一个是当研究者提供了所有出版物时,如何批量下载,以及根据批量下载后的PDF生成文献引用信息,继而根据【google学术引用次数】找出她最重要的论文;一个是,如何保存任意网页,并根据自己个性化需求,开发自定义的translators,从而打造一个个性化的知识库。